

画像認識技術とトトパターン
なんだかよく分からないタイトルですが。。
機械学習技術を用いてトトくじの予想をすることについて、現状における問題点を整理してみたいと思います。ディープラーニング自体については参考になるような情報は多くあります。しかしトトくじ予想と機械学習を関連付けた資料などというものはまったくありません。すべて僕の妄想ですね。(ほかにチャレンジしている方もいるかもしれないが。。)
ディープラーニングの画像認識
ディープラーニングがどんなものであるか?は、すでにネットに多くの情報があります。とくにチュートリアルなどでは画像認識についてのものが多い。
つまり たくさんの画像から ”特定の種類のものについて、それが何であるか?そのラベルを言い当てる” というものですね。
1、あらかじめ学習データとして ”画像とラベル” を認識させておく。
2、つぎに新たな画像をみせて、それがどのラベルに該当するのか?を推測させる。
おそらくこういう理解でいいと思います。
この推測するときの根拠となる特徴を見極める事・・これにポイントがあります。
人間が画像を目で見て ”それが何であるか?” 判断するときには一体何がおこっているんだろ?
色彩とか質感、周囲の状況などを瞬時に見極めて答えを出していますね。これと同じことを機械的に判断させる。
画像はまったく別のものではあるけれども、全体として、 ”それは猫であり、たとえば獲物を狙っている場面である” というようなことを自動的に判断するんですね。
ディープラーニングでは、この ”特徴” を機械自身が見出します。人間がいちいち指示するのではなくて、たくさんの画像を見て、その特徴を自らが学習するわけです。そしてその自らが見出した特徴でもって ”それがなんであるか?” を判断する。
人間が予想するときのプロセス
話をトトくじ予想に限って進めてみましょう。
home と、away ・・今回はどう勝負がつくのか?
これが問題です。
過去の試合データはある。ただし過去と現在では状況が違う。メンバーも若干入れ替わっているかもしれないし、監督も変わって戦術も変化してるかもしれません。
”猫の画像認識” とはおなじ ”パターン分類” でもずいぶん状況が違いますね。
言葉で整理すると次のようになるかと思います。
「同じパターンを示しているが、ラベル(結果)は違ってくる可能性がある」
同じパターンなら必ず同じラベルになるとは限らない・・というのがサッカーだと思うんですね。。まあ、これを言っちゃたらお話にならない。。なので、できるだけ可能性の高いほうに賭けるわけで。
いくつかパターンを示してみますね。
1、点が獲れているか?
2、ディフェンスは機能しているか?
3、引いて守って、カウンター?
4、実力差を考えてドロー狙い?
5、レギュラー選手の欠場とか?
サッカー批評などをみていると、いくつか類型?みたいなものがあることに気がつきます。監督、選手たちのインタビューとか。
そういう情報と、直前の試合ぶりなどから総合して我々は次回の試合展開を予想して判断を下します。
こういった判断のプロセスを機械にやらせるにはどうすればいいのか?
”画像とラベル” を置き換えて考えてみる
さて、理屈というか観念は理解している。あとは方法だけです。
ディープラーニングにおいては画像・・イメージをどうやって認識しているか?
このあたりは次の資料で理解してみましょう。

僕自身もまだまだなんですけど、この記事にはヒントがある。
画像データを数値データに変換しているんですね。
トトにおけるデータは画像ではなくて、まあ数値なんですね。数値でもあり名義属性の値でもある。
ここが一番ひっかかっていた箇所なんですけれども、 ”どういう値を与えればいいのか?”
問題はここです。
名義尺度が指定できる?
現在、僕が使用している WEKA では 数値属性であれ名義属性でも、そしてその混在形でも動かすことができます。ただしデータによって使えるアルゴリズムは制限されますが。
パイソンでは確かそういう尺度(数値とか名義とか・・)はかなり厳格で、制限されていたように思います。まあ使いにくいわけです。つまずきの原因は、まさに ”そこにある” のですが、どうもこの記事を読み進める限りでは、かなり自由度が高いような気がします。
データ形式も CSV でOKなところもいいですね。
テキスト(日本語?)とか認識してくれるかどうかはまったく分かりませんけれども、とりあえずこの ”H2O” を試してみたい。
さて、はなしを戻すと、データの基本は ”数値” であります。トトの場合は ゴール であり、失点 が元ですよね。つぎに重要なのが チーム名 です。
これはいったいどうやって表現すればいいのでしょうか?
ようするに 画像=対戦カード と置き換える。この場合、どう考えていけばいいか?
それぞれ過去と現在では状況の異なるチームをどうやって一枚の画像に置き換えることができるのか?
これは抽象的な意味で言ってることであり、実際に一枚の画像にするわけじゃあないです。データの羅列によって ”それ” を表現するわけですね。
そうして特長量を計算させて、それがどのラベルに属するか?を計算させる。
これが僕のやってみたいことです。
概念は分かるが本質的になにかが違う?
さて。。
いろいろ考えてはいるのですが、やっぱりなにか違う。
それは
「同じパターンを示しているが、ラベル(結果)は違ってくる可能性がある」
やっぱりココ。
考えすぎかもな、やってみるしかない。
H2O ディープラーニング 。。
検索したら意外とヒット!!
みんな情報早い。。てかすげーわ。
追記
さて、トト予想と機械学習について、追記したいと思います。
内容は 機械学習のためのデータ構成について。
たとえば浦和が浦和であることをデータに示すにはどうすればいいか?
なんか妙なタイトルですが・・
現状使っているWEKAにおいては 浦和というチームを示すのに ”浦和” と漢字テキストで表しています。文字通り ”そのまま” ですね。もう少し手間を惜しまなければ、たとえば直前の試合では誰がどのポジションで出場して、どういうプレイをしたか?とか、相手チームに対して何ゴールして何失点したか?などという情報を付加することもできます。
これを機械・・プログラムの認識と人間の認識で比較してみる。
機械の場合は、ただの漢字テキストとして浦和を認識してます。ほかに何も情報を持たない。当然過ぎますがそういうことです。上に書いたように、いろいろ情報を付加して、それを浦和として認識させることももちろん可能です。
人間の場合は、”浦和” と聞くといろんなものを(イメージを)想起します。なぜかというと、これまでに ”浦和” という言葉、単語にたいしての ”情報の蓄積” があるからですね。もちろん人によってそのイメージ、想起されるものは違ってくるはず。
これを機械学習では ”浦和の属性” つまり 対象となるものを表す属性 という。
ディープラーニングの一番の特徴は、この対象を表す属性・・つまり特徴量を自分で学習する。非常に多くの特徴から ”他のものと区別する特徴” をみずからが見つけて構築するわけです。何度も書いていますがそういうこと。
このことから私がすることは ”できるだけ多くのデータを与える” ことだけでいいのかなと。あとは深層学習にまかせる。
問題になるのはチームというのは常に一定ではないこと
ここでいわゆる 猫画像 と サッカーチーム というものを対比させて考えてみます。
さて、猫 っていうのは まあ、常に一定ですね。いつ見ても同じ姿、格好をしている。確かに行動は変化するけれども(たとえばエサを食べていたり、寝そべっていたり、毛を逆立てて怒っていたり・・)していても猫に変わりはありません。
サッカーチームというのも常に(通常は)イレブンであり、同じユニフォームを着て、J1レベルであれば、そのような動きでサッカーをする。
ただ同じ対戦相手であっても、再び戦えば同じ結果になるかというとそうではない。なにが違うかというと、出場選手であったり、監督の指示が違ってたりする、あとは試合展開が想定と違っていたり、不測の事態によりメンバーが交代したり、PKを取られたりとかいろいろありますね。
まあ、いろいろ考えられますが、一番は ”コンディション” という言葉で表されるものかなと思うんですね。いわゆる調子です。調子。調整。
コンディションが良ければいつもより良いプレイができるとか、あとチーム内のコミュニケーションが上手くとれて、それぞれの機能が発揮されている状態とか。
今現在、”どういう調子にあるのか?” これが波、勝負の波の正体なんではないのかな。つまり同じ浦和でも良い浦和と悪い浦和ってのがあって、もちろんその中間みたいな状態もあると。
そういうのをあえてデータで表現しようとしたらどうするのかなと。
このとき ”どうするのか?” と考えるのは ディープラーニングでいえば 特徴量の抽出 というやつです。たぶんそう。これを人力でやるってのは相当に大変でして、物凄い労力が必要になると思っています。
まあデータを羅列、つまり考えられる属性を並べ上げて、ひとつのビッグデータをつくるってのも相当大変な作業ではあるのですが。。
データ構成のひとつの仮説
さて、非常に長々と思いつくまま書いてきましたが、ここらで現状のまとめを記録しておきましょう。
1、最新のチーム状況のデータ化
これは同じチームでも常に一定ではないという事実から考えたこと。具体的には次のような目安で考えてみる。
直近5試合の勝敗状況をひとつのデータとしてまとめて ”○○チーム” とする。つまり5試合分で次回予測のためのデータとする。これでひとつのインスタンスを構成するということ。
アイデアとしては別に新しくもなんともないです。トトワンというサッカー予想サイトにある ”データ詳細” に書いてあるようなことを、ただ整理してまとめていくだけの作業ですね。かなり面倒ですが。。
こういう形式のデータを逐一つくって累積させていきます。データは各チームごとに作ります。J1だけでも18チームあるから相当なヴォリューム、作業量になりますね。
テキスト説明では分かりにくいので、参考画像を載せておきましょう。
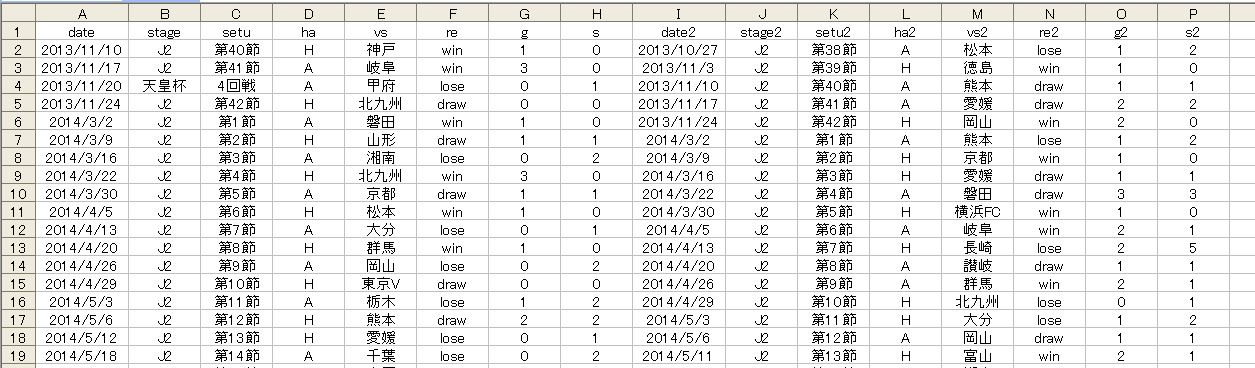
これは上で述べた ディープラーニング用データではありません。
現在使用中のWEKA用のデータです。同じようなデータが2列並んでいます。左がホーム、右がアウエイです。トト753の札幌ー福岡のデータです。
これのそれぞれ5回分の試合データを横に並べたものが現在考えているデータ構成となります。直前5試合分が次回予想のためのデータとなるイメージですね。
ちょっと分かりずらいかも。。
データ元は ファンタジーサッカー研究室・・ファンサカ ですね。これをちょっといじってあります。とりあえず簡単なデータからはじめようと思ったので。あまりにも手がかかりすぎるとイヤになりますから。
今日はここまで。おわり。

コメント