
トレーニングデータとテストデータの属性タイプをきちんと合わせる。
これは基本中の基本。
トレーニングデータとテストデータの属性タイプがきちんと合っていないと上手く機能させることができません。調整の仕方は簡単です。
まずトレーニングデータを読み込ませます。この時点ではほぼエラーになることはありません。
つぎにパースをするんですが、重要なのはこの前に各属性タイプを決めることです。
一応、自動で属性タイプを勝手に判断して選択はしてくれます。しかし、テストデータも全く同じ属性タイプを選択しないとちゃんと動かなくなります。なので、パースボタンを押す前に確認だけしておきます。
必要に応じて属性タイプを変更してもいいですが、その場合はテストデータも合わせること。こうすることによってほぼエラーは起きないです。
注意! 属性タイプの選択によっては予測結果がガラリと変わる可能性があります。
実際の予測においては、属性タイプの変更はかなり影響を持ちます。なので、いくつか試してみて、最良の属性タイプを探す必要があります。テストにおいて良い予測精度を示すようにしていきます。
単純な例ですが、数値 が良いのか、あるいは 名義 としてやった方が良いのか? というような感じです。
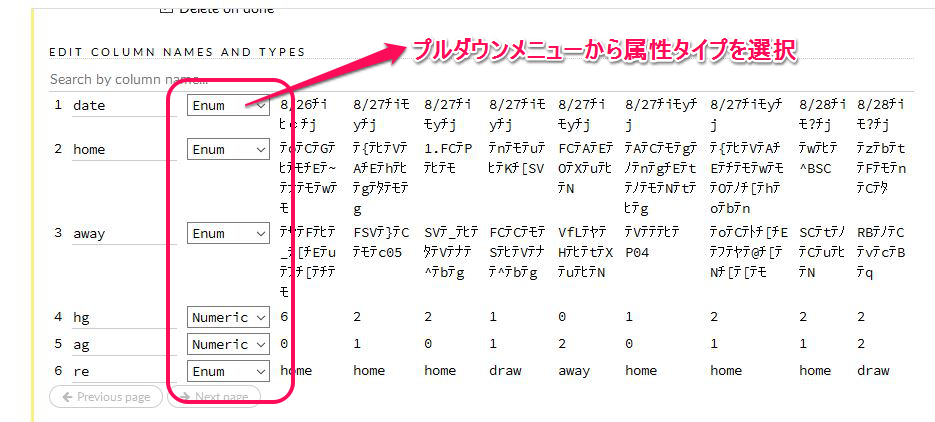
上の画像の例は、自動で選択された属性タイプです。これを変えていきます。赤枠の中をクリックすると属性のメニューが出るので、そこから新たに選択し直します。
例えば、数値である numeric を、Enum にすると 名義属性として分類予測できるようになります。
文字化け部分は、予測自体には影響を与えないのでそのままにしてあります。パースをすればちゃんと識別できるように変換されます。読み込ませる前に半角英数でデータが作成してあれば、そのまま表示されるはずです。


コメント