
第840回トトくじ予想
いろいろ予測方法について試してはいますが、今回は新たな取り組みはありません。以下にサラッと予測した結果を挙げておきます。
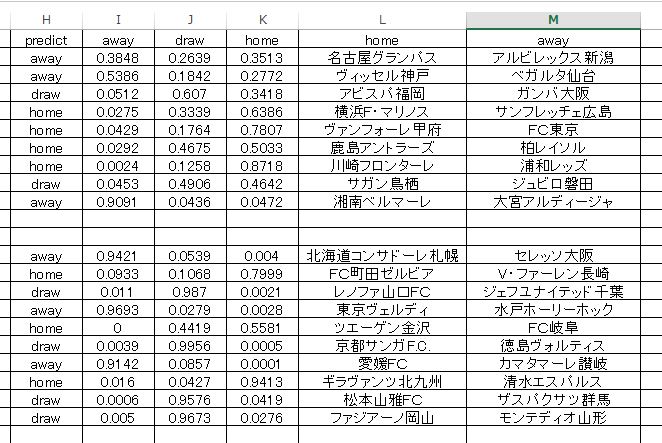 また スベるんじゃないか・・ 自信はまったくないです。
また スベるんじゃないか・・ 自信はまったくないです。
予想結果と検証
この記事を書いている時点で J2 3試合 が終了しました。上の予想について若干説明をします。
予想手順としてはひどく簡単なものです。トレーニングデータに対するクロスバリデーションを 5 にセットし、あとは活性化関数をグリッドしただけ。その他の設定はデフォルトのままです。トレーニングデータは今季の累積です。(1部と2部は分けています)
見ての通り、のっけからハズレていますね。あまり良い結果は期待できそうにもありません。後出しとなりますが、以下にもうひとつ予想表を載せます。記録のために予想手順もいっしょに書いておきます。
1、トレーニングデータを指定したらクロスバリデーションもセットする。回数は5~10の範囲で。
2、つぎに活性化関数をグリッドする。
3、あとのパラメーターはいじらずにデフォルトでいったんこれで走らせる。
4、グリッドサーチの結果からいちばん良い活性化関数を選択
5、ふたたびクロスバリデーションをセットし、選択した活性化関数を指定する。
6、ここで正則化の数値をグリッドします。
7、1回目の正則化グリドサーチは荒く行います。2回目以降は次第に範囲を狭めるように行います。
8、正則化グリッドの結果をみて、いちばん優れていると思われる数値を選択。
9、最後にもう一度、一連の作業で選ばれた数値や活性化関数でもってクロスバリデーションを行って予測モデルを構築します。
これで十分だとは言えませんが、少なくとも何もしないよりは良いモデルができるのではと思います。まだ試行錯誤中なので何とも言えません。以下がこのやり方で構築したモデルによる予測です。
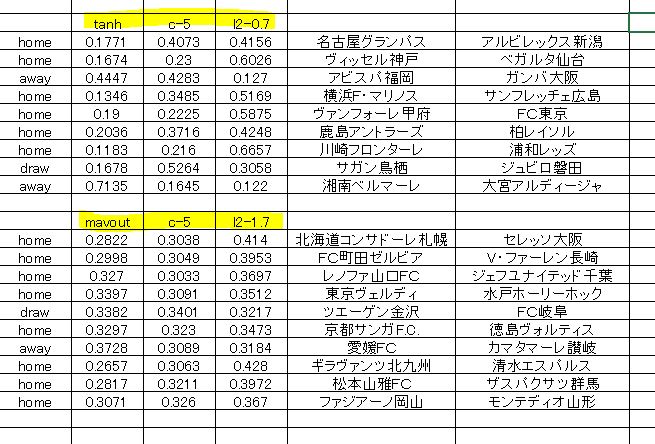
確率の数値は例によって 左側がawayとなっています。真ん中がdraw,右側はhomeです。予想は一番数値が大きいものが選ばれています。黄色のマーキングは1部、2部 それぞれの活性化関数とクロスバリデーションの回数、そして正則化項目の L2 の数値 となっています。
L1 に関しては、上の予想では ゼロ を選択しています。
現時点でJ2は良い予測結果を示しています。ちなみに、この予想によるトト公式サイトによる配当予想はものすごく低いです。比較的順当な予想ということですね。
さて、J2の部がすべて終わりました。追記となりますが少し振り返ってみます。
一番最初に挙げたJ2の予測はパッと見てすぐわかる通り ほとんど当たっていません。よくない予想です。確率配分もよく見てみると ものすごく極端に偏っているのが分かります。それに比べて後出しの予想のほうは 確率配分がいくらかマイルドになっているのが確認できます。
最初の予測と二つ目の予測の違いは以下の通りです。
1、トレーニングデータは共通だが、テストデータの中身が少しだけ違う。
2、最初のモデルは正則化項目の数値は L1,L2 とも ゼロ。後出しモデルは L1 はゼロのままで、L2の数値に関しては二度ほど行っている。
3、活性化関数は両者ともグリッドをかけて選択している。今回のデータでは 前者が tanh with doroppout で、後者が maxout となっている。
活性化関数の選び方については調べてはいますけど、何が基準になるのかよく分からないです。そもそも関数自体に良し悪しはなくて、データに対して適切に選べばいいだけの話だとは思うのですが、その基準というか考え方がよく理解できていません。現状では 評価関数の数値を頼りに選ぶしかないです。
今回の J2-9節 の予想、前者はまったくダメでした。やっぱりちゃんとしたテストデータを用意しなければいけません。それに面倒ですが、正則化もやらないとダメです。(現状でのやり方がベストだとは思っていませんが)比較すると後者の予測のほうがまだ出来が良いと感じます。結果的に 4/10 しか正解していませんが、確率配分も含めて考えると、後者の方が明らかに良いです。
J1-8節 については また追記します。
J1 8節 終了しました。予想は全くダメですね。おおきく期待を裏切る結果となっています。同じように支持率のほうも期待を裏切ったようで、1等当選該当なし キャリーオーバー となりました。
ディープラーニングを使った予想は、上手く特徴を捉えている思われる枠もありますし、逆にまったくかみ合わない枠、組み合わせもあったりして、全体的に 捉えどころがない といった感触です。全く使えないわけでもなく、かといって信頼に足る結果も得られない といった感じ。むずかしい。
同じ H2O の ランダムフォレスト による予測もディープラーニングと並行してテストを行いました。モデルの分かりやすさ と、安定性 いう点ではこちらの方が向いているかもしれません。データはすべてディープラーニングと同じものを使用しています。クロスバリデーションは10にセットしてあります。そしてこの予想では keep_cross_validation_predictions という機能を オン にしてモデル構築をしてあります。
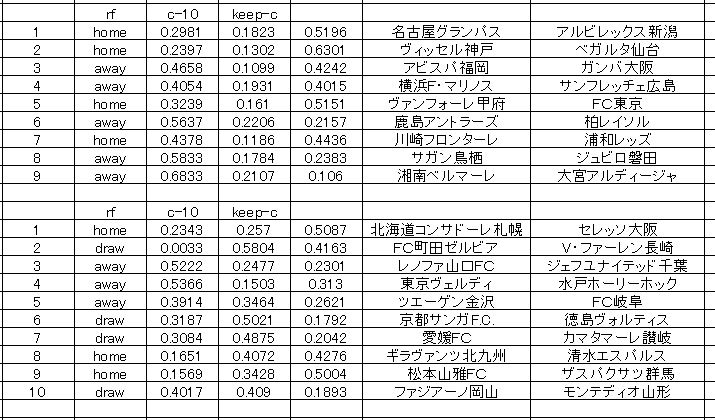
全体的には良い予想を出力していると思います。いつものように確率配分は真ん中のドローを挟んで逆ですからね。左側がawayです。
次回トトはまたリーグ戦のようですので、引き続きいろいろ予想を出してみたいと思います。J1,J2とも ランダムフォレストを主軸の予想手段として考えた方が良いかもしれません。


コメント