
この記事では 実践的にH2Oの各種アルゴリズムにおいて、グリッドサーチを使う方法について、自身の理解を深めるために書きます。
対象となる事例は、サッカーにおける過去試合のスタッツから次戦の組み合わせ対象試合の結果を予測する というものです。スタッツの意味は下記の通り。
スタッツ【stats】とは 統計の意のスタティスティックス(statistics)から、スポーツで,選手のプレー内容に関する統計数値のことを意味します。
以下に私の行ったことを順に書いていきます。合わせて なぜそうしたか? という考え方も記録しておこうと思います。
統計数値(スタッツ)にはパターンがあるのか?
やみくもに突っ走ってきた機械学習によるスポーツ勝敗予測。ほぼ独学というかネットで拾ってきた断片的知識でもって適当に予測してきました。傍から見るとメチャクチャやっているように見えるであろうこの試み、私自身はいたって真面目に取り組んでいるつもりです。
まず最初に考えたことは、予測対象事例(トレーニングデータ)にパターンがあれば必ずそのパターンを見つけることができるし、結果の分からない未知のデータも優れた予測モデルさえあれば正確に予測できるはずだ ということ。裏を返せば ランダムデータ (パターンがない、もしくはランダム性が極めて高いトレーニングデータ)では、いくら予測能力を高めようと工夫しても、性能の高い予測モデルは作ることができず、どうしようもないということです。
パターンによる分類予測の成功には前提条件があり、ひとつはトレーニングデータに法則性や規則性がみられること。完全なランダムではないということと、もうひとつはテストデータ(結果の分からない未知のデータ)にも、トレーニングデータと同じような法則性や規則性が見られることです。つまり デタラメ ではないということです。
ここしばらくは 自作データ によって予測モデルを作成し、実際の試合結果と照合してなんとか性能の良い 分類予測モデル を作ろうと試みてきました。しかしながら自作データの質がイマイチで、どうも自作データはランダム性が高いのでは? という結論に達しました。つまりは デタラメ を寄せ集めたデータなのではないか? ということです。
まずは正規の過去試合スタッツにおいて 本当にランダムではなくてパターンがあるのかどうかについて調べてみることにしました。調べ方は以下のようにしました。
1、正式なスタッツを使ってホーム側とアウェイ側を同じインスタンスにまとめる。すでに終わっている試合の内容、数値をエクセルなどを使って同じ行に並べるだけです。データ元はJリーグ公式サイトや、フットボールラボ などから得ます。
2、上で作ったデータを機械学習させます。私の場合は H2O-3 のディープラーニングを使いました。具体的には予測モデルを構築するわけですが、その際に交差検定をします。原理的には データにパターンがあれば確実に検定結果が向上します。つまりエラー率が下がります。
上で述べたように、ちゃんとパターンが認識されていれば 交差検定(目隠しテスト)でもある程度の予測精度は出せるはずです。そして 過学習などを抑える、なおかつ 予測精度 を高める工夫(各種パラメーターへの適切な値の入力)をすれば実際の予測においても高い予測性能を発揮するはずです。つまりは汎化性能を向上させるということです。
次は H2O-3 のディープラーニング限定で汎化性能を向上させるために行ったことを書きます。
H2O-3 の ディープラーニングパラメーター
まず、特殊なパラメーターは後にして基本からやります。与えているデータ(教師データ)とテスト用データは両者に共通するパターンを持っているという前提ですので、正則化などの調整をやって、適切な交差検定をすれば、パターンのマッチングによる良い予測結果が得られるはずです。そして未知のデータに対しても良い予測を期待することができるはずです。これが繰り返し述べている基本的な予測モデル構築の考え方です。
正則化については、その重要性について認識はしていたものの、適切なやり方が分からず放置していたのですが、あらためてその概要について以下にまとめます。
L1正則化は「不要なパラメータを削りたい」(次元・特徴量削減)という時によく使われる。L2正則化の場合は過学習を抑えて汎化された滑らかなモデルを得やすい
引用は RでL1 / L2正則化を実践する から。L1はデータをスカスカにする とか言う表現がされます。つまり あまり重要でない属性の値をゼロにしてしまうわけです。スパース Sparse とも表現され、まばら とか、疎 、希薄 とか、そういう意味になると思われます。んで、これをやると何が良いか 嬉しいか というと・・
より本質的には、適切にデータを捨てることを選択した方が良い結果に到達できる可能性が高い
これはネット上から拾ってきた言葉です。意味としては文脈にマッチしていると思います。要らないデータは捨てた方が良いということ。H2O-3 では、その正則化の判定の度合いを数値で入力するというわけです。L2の正則化については文字通りで、過学習を抑えて予測モデルの汎化性能を高める効果があります。L1,L2ともグリッドサーチで適切な値を入力して探索することができるようになっています。
問題は、どんな数値を入力してやればいいか? まったく知識がないものですから何をすればいいか皆目分かりません。モデル構築のデフォルト画面ではゼロが入力してあります。なんとなくゼロに近い数字なのかな? と考えましたが、桁を変えていくつかテストしてみることにしました。その結果デカすぎてもエラーになり、マイナスもエラーとなりました。具体的には次のセクションで書いています。知識がある人が見たら笑えるレベルだと思いますが。
変数をいくつか指定してグリッドサーチをする場合の具体的なやり方
-1;0;1 とか、0.1;1;10 などと書きます。(これは あくまで例です。悪い見本なので真似してはいけません。)数値はもちろん半角英数で書きます。注意点としては 数値の区切りにはスペースを入れずに、セミコロン ; で繋ぎます。基本的に変数のタイプが double となっているパラメーターには、このように数値を入れます。
これらの入力欄には 浮動小数点 を入力するらしいのですが知識がないので触れないでおきます。正直いって頭が痛くなります。理解しておいたほうがよいというのは分かるんですが頭が受け付けない。。
正則化項目の数値の入力の実際例を以下に示します。
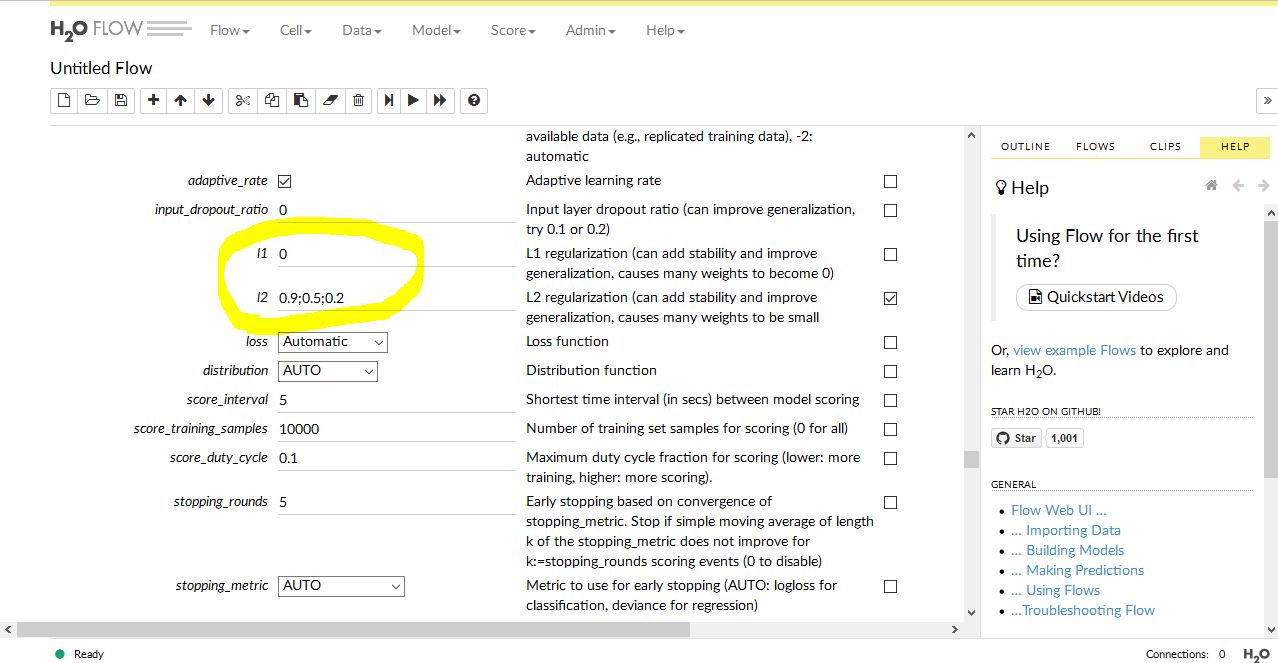 黄色枠で示した箇所が正則化の項目です。L1はゼロのままです。L2 には 0.9;0.5;0.2 と入力してグリッドのチェックをオンにしてあります。数値を書き込む前にデフォルトの状態でチェックをオンにし、そのあとで入力欄のゼロを消して新たな数値をセミコロンで区切りながら入力していきます。
黄色枠で示した箇所が正則化の項目です。L1はゼロのままです。L2 には 0.9;0.5;0.2 と入力してグリッドのチェックをオンにしてあります。数値を書き込む前にデフォルトの状態でチェックをオンにし、そのあとで入力欄のゼロを消して新たな数値をセミコロンで区切りながら入力していきます。
一応この状態でモデルを構築して、未知のデータについて予測させたものを次のセクションで載せておきます。
L2 をグリッドサーチで設定してクロスバリデーションを行って予測モデルを構築してみた結果 やっぱり効果はあったのか?
今回は単純なテストという位置付けで行いました。したがってその他のグリッドサーチ(活性化関数とか)は正則化と同時には行っていません。トレーニングデータに対するクロスバリデーションを 5 にしただけであり、L2以外はデフォルトとなっています。まずは未知データのテスト結果・・予測結果から見ていきます。
予測対象は J1-第5節 です。トレーニングデータは今季の J1 の第1節から第4節の実際の数値データです。それぞれのチームの各節における試合のデータを細工せずにそのまま教師データとして使っています。(パーセントやその他の記号、単位などは削除してあり、numericとして認識されるようにはしてあります。)目的変数は結果そのものであり、3WAYの試合結果となっています。テストデータのほうの内容は明らかにはできませんが、トレ―ニングデータと同じデータフレームで数値を入力してあります。(じつはココがもっとも肝な部分であり、デタラメな数値が入ると予測が上手くいかない)
とりあえず記録のために今回のテストのパラメーター設定を残しておきます。活性化関数は Tanh を指定しています。理由は特にありません。適当です。グリッドサーチの結果、L2の数値は 0.5 が選ばれています。
| label | type | level | actual_value | default_value |
|---|---|---|---|---|
| model_id | Key | critical | Grid_DeepLearning_Key_Frame__j1_5_train_Official.hex_model_Mozilla_1461051653625_4_model_1 | |
| training_frame | Key | critical | Key_Frame__j1_5_train_Official.hex | |
| validation_frame | Key | critical | · | |
| nfolds | int | critical | 5 | 0 |
| keep_cross_validation_predictions | boolean | expert | false | false |
| fold_assignment | enum | secondary | AUTO | AUTO |
| fold_column | VecSpecifier | secondary | · | |
| response_column | VecSpecifier | critical | result | |
| ignored_columns | string[] | critical | section | |
| ignore_const_cols | boolean | critical | true | true |
| score_each_iteration | boolean | secondary | false | false |
| weights_column | VecSpecifier | secondary | · | |
| offset_column | VecSpecifier | secondary | · | |
| balance_classes | boolean | secondary | false | false |
| class_sampling_factors | float[] | expert | · | |
| max_after_balance_size | float | expert | 5 | 5 |
| max_confusion_matrix_size | int | secondary | 20 | 20 |
| max_hit_ratio_k | int | secondary | 0 | 0 |
| checkpoint | Key | secondary | · | |
| overwrite_with_best_model | boolean | expert | false | true |
| use_all_factor_levels | boolean | secondary | true | true |
| standardize | boolean | secondary | true | true |
| activation | enum | critical | Tanh | Rectifier |
| hidden | int[] | critical | 200200 | 200200 |
| epochs | double | critical | 9.130610079575597 | 10 |
| train_samples_per_iteration | long | secondary | -2 | -2 |
| target_ratio_comm_to_comp | double | expert | 0.05 | 0.05 |
| seed | long | expert | 8612431013877265000 | 7566244619125769000 |
| adaptive_rate | boolean | secondary | true | true |
| rho | double | expert | 0.99 | 0.99 |
| epsilon | double | expert | 1e-8 | 1e-8 |
| rate | double | expert | 0.005 | 0.005 |
| rate_annealing | double | expert | 0.000001 | 0.000001 |
| rate_decay | double | expert | 1 | 1 |
| momentum_start | double | expert | 0 | 0 |
| momentum_ramp | double | expert | 1000000 | 1000000 |
| momentum_stable | double | expert | 0 | 0 |
| nesterov_accelerated_gradient | boolean | expert | true | true |
| input_dropout_ratio | double | secondary | 0 | 0 |
| hidden_dropout_ratios | double[] | secondary | · | |
| l1 | double | secondary | 0 | 0 |
| l2 | double | secondary | 0.5 | 0 |
| max_w2 | float | expert | Infinity | Infinity |
| initial_weight_distribution | enum | expert | UniformAdaptive | UniformAdaptive |
| initial_weight_scale | double | expert | 1 | 1 |
| loss | enum | secondary | Automatic | Automatic |
| distribution | enum | secondary | AUTO | AUTO |
| quantile_alpha | double | secondary | 0.5 | 0.5 |
| tweedie_power | double | secondary | 1.5 | 1.5 |
| score_interval | double | secondary | 5 | 5 |
| score_training_samples | long | secondary | 10000 | 10000 |
| score_validation_samples | long | secondary | 0 | 0 |
| score_duty_cycle | double | secondary | 0.1 | 0.1 |
| classification_stop | double | expert | 0 | 0 |
| regression_stop | double | expert | 0.000001 | 0.000001 |
| stopping_rounds | int | secondary | 0 | 5 |
| stopping_metric | enum | secondary | AUTO | AUTO |
| stopping_tolerance | double | secondary | 0 | 0 |
| max_runtime_secs | double | secondary | 0 | 0 |
| score_validation_sampling | enum | expert | Uniform | Uniform |
| diagnostics | boolean | expert | true | true |
| fast_mode | boolean | expert | true | true |
| force_load_balance | boolean | expert | true | true |
| variable_importances | boolean | critical | false | false |
| replicate_training_data | boolean | secondary | true | true |
| single_node_mode | boolean | expert | false | false |
| shuffle_training_data | boolean | expert | false | false |
| missing_values_handling | enum | expert | MeanImputation | MeanImputation |
| quiet_mode | boolean | expert | false | false |
| autoencoder | boolean | secondary | false | false |
| sparse | boolean | expert | false | false |
| col_major | boolean | expert | false | false |
| average_activation | double | expert | 0 | 0 |
| sparsity_beta | double | expert | 0 | 0 |
| max_categorical_features | int | expert | 2147483647 | 2147483647 |
| reproducible | boolean | expert | false | false |
| export_weights_and_biases | boolean | expert | false | false |
| elastic_averaging | boolean | expert | false | false |
| elastic_averaging_moving_rate | double | expert | 0.9 | 0.9 |
| elastic_averaging_regularization | double | expert | 0.001 |
この予測モデルを使ってJ1-第5節の予想をした結果が以下です。
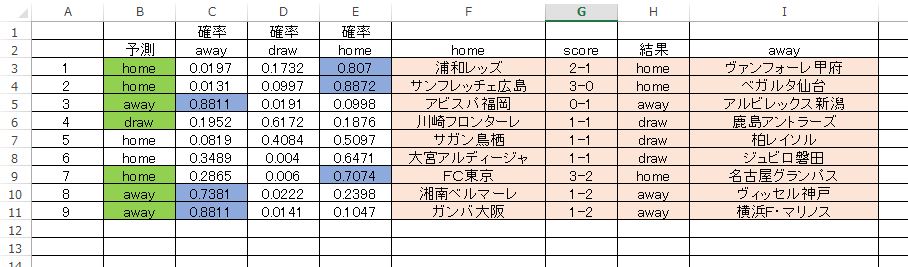
グリーンが正解枠で 7/9 の正解率です。完全にハズレは2枠、いずれもドローが予測できていません。なかでも 大宮ー磐田 は完全に読めていないです。青のマーキングは予測確率が 70%から80%台になっている箇所で正解しているものをマークしました。見て分かる通り、このような比較的大きな確率を示している枠は、ほぼすべて正解しています。大きな数値で外しているのは 鳥栖ー柏 のみです。この枠は home と、draw で確率が割れています。予想としては悪くないような気もしますが、ハズレはハズレですからね。ダメ。
しかし自分では かなり予測が成功していると感じます。予測精度が向上した要因がどこにあるのか 正確にはつかめていませんが、いろいろと改善の余地はありそうな結果が得られたと思っています。
今週末にはリーグ戦が控えていますので、もう少し詰めて考えたいと思います。つづく。
予測モデルの評価について
予測モデルの良し悪しってどう評価すればいいんだろう?
これはとても大きな課題であるわけで、予測を続けるにあたっては絶対に直面する問題なわけです。同じ対象事例について、いろいろな手法で、あるいはデータフォーマットで何種類も予測モデルをつくることは簡単なことです。いちばん難しいのは それらの中から信頼できる最良の予測モデルを見つけること。これがブレると本当に何をやっていいのか分からなくなってきます。
モデルを評価するにはいくつかの指数があります。H2O-3 においては logloss という指数で評価され順位が決められるようです。マルチクラス(3群以上の分類モデル)における評価関数で ゼロ に近いほど精度が高いというもの。グリッドサーチによっていくつかモデルが構築された場合に自動的に 一番 logloss の値が低いモデル をリストのトップに表示してくれます。考えてみればこういったベストな予測モデルというのは、そのトレーニングデータに対してのみ有効なセッティングであって、データを変えれば、そのつどベストなセッティングを探索する必要があるのかどうか?
繰り返しになりますが 問題は、そのモデルで選ばれた各種パラメーターの設定が トレーニングデータを変えた際に再び適用できるものなのかどうか? といったことがあります。活性化関数もそうですし、L2 などの 正則化の数値もそうです。
事実、試してみて分かったことは、良い結果を残したセッティングは他のトレーニングデータによる予測では同じような良い結果を残してはくれない ということです。
おそらくベストなセッティングというのはトレーニングデータによって毎回変わります。あと その他のパラメーターの設定によっても変化するし、クロスバリーデーションによっても変化します。結局のところ、その都度によってモデルの信頼度がガラッと変化します。絶対的な基準というか評価ができないんですね。それに一番評価が良いモデルだといっても、実務上の評価、つまり目で見て分かる予測結果の正しさには必ずしもつながることはありません。
まとめます。
対象事例の性質によるところが大きいと思いますが、このサッカー勝敗予想においては、毎回ベストな設定を探す必要があります。じつに面倒で大変な作業なんですが 何かのモノの特徴をつかみ取って分類する単純な作業 ではないと感じます。
予測モデルを構築する際の基準となる設定をどこに持ってくればいいんだろう?
ディープラーニングは設定次第でガンガン結果が変化します。何を基準に考えればいいのかよく分からない部分があります。理解不足なのかもしれませんが、モデル構築の基準点をどこに置けばいいのかよく分からないんですね。たとえば活性化関数をどれかひとつ選んで、それを基準にその他のパラメーターを調整していくとか、そういう統一化された作業手順というのを自分で作るしかないのかなとも思います。
そういった作業のなかでベストなモデルの組み立て方というのを手探りで確かめつつ確立するしかないです。なにしろ お手本 など何もないですからね。
H2O のディープラーニング限定での話なんですが、モデル構築の際には、まず最初にデータを選択します。教師となるデータです。そして目的変数を選択。その過程でクロスバリデーションの有無を決めます。あと回数も。
つぎに活性化関数を選択します。これを決めないことには先に進むことができません。んで、何を基準にこの活性化関数を選べばいいのか?
最初にここで躓きます。明確な指針があればいいのですが、どうもイマイチ分からない。仕方なくここでグリッドサーチをかけます。いちばん良い評価が出る関数を選択するわけです。具体的にはloglossの値で決定されます。マルチクラスの分類問題ではこの数値が低いほど良いモデルだということです。
ここまでの作業でとりあえずは活性化関数が決まりました。あくまでデフォルト設定における最良モデルというわけで、この選択がベストなものかどうかは分かりません。その他のパラメータを変更すれば、先に選択されたベストな活性化関数も変わってくる可能性があります。こういうところが非常に使いづらく分かりにくい部分です。


コメント