
- ディープラーニング H2O を 具体的目的のために使う 準備と方法
- 機械学習による株価予測の現状
- H2O について
- パラメーターに関する記述
- Welcome to H2O 3.0
- 新しくなった H2O 実際に使ってみよう
- H2O ダウンロードはできたが何をしていいか分からない方への提案
- どんなデータを与えればいいのか? 参考サイトのデータからヒントを得る。
- スクレイピング技術で関心のあるデータを獲りにいく。
- データ構成について
- 何を対象とするか? 何を予測したいと考えるのか? これによってデータの作り方は大きく変わる。
- H2O データのインポートの方法 データの読み込ませについて。日本語によるデータを文字化けさせずに読み込ませる。
- 日本語データの文字化けを正常に表示させる方法 新ヴァージョン対応
- CSVデータの保存時における名前は日本語を使ってはいけません。エラーになるようです。また属性名は英数字を使った方が良いです。
- ディープラーニングを使った予測モデルの構築 グリッドサーチを使ってパラメーターを自動調整する
ディープラーニング H2O を 具体的目的のために使う 準備と方法
こちらの記事は随時 更新しております。H2Oとは直接関係しない内容もあります。しかし全体としてみれば 機械学習の応用 ということにつながります。未来予測の技術としての機械学習、そのひとつとしてディープラーニングがあります。
機械学習による株価予測の現状
H2Oに入る前に興味深い記事がありましたので、以下にリンクを残します。

この記事では、どういった考え方で株価を予測しているか? について詳しく書かれています。技術的なことには それほど触れていませんので理解しやすいと思います。私が思い描いているのも、こういった応用例だと考えてください。
動的な将来をどうやって予測するか? その方法のひとつとしてディープラーニングがあり、そしていろいろなプラットフォームがあり、H2Oもそのひとつ というスタンスで考えています。
H2O について
日本語による情報が不足気味のH2O。以下の記事では具体的に使うためにはどうすればいいのか? ということについて書いています。僕自身が不明な点もたくさんありますので時間をかけて理解していきたいと考えています。
しばらく触ってないうちに なんだかヴァージョンアップされてるような。。現在は H2O-3 らしいです。どんどん改良されていくみたいなので楽しみです。
さて本題のディープラーニングについて。情報はすべて英語です。精読はまだですが、とりあえず資料だけ記録しておきます。
パラメーターに関する記述
H2Oのディープラーニングにはグリッドサーチ機能があります。ヘルプにもありますが、モデル構築をする際にオプションで validation_frame というモデルの精度を評価するために使用されるデータセットを選択する箇所があります。
オプションなので どうしてもする必要はなく、特に何も選択しなくてもモデル構築はできます。しかし予測精度を高めるためには是非使用したい機能です。手動で より高度な操作もできるようですが、専門的な知識も必要なことなのであまりおすすめできるものではないです。
より簡単に精度の高い予測モデルを作成するためには、モデル構築用のデータセットと検証用のデータセットのふたつが必要だというわけです。フォーマットというかデータの形式はふたつとも合わせておく必要があるかと思います。
僕自身はまだ試行していないので、結果が分かりしだい追記したいと思います。
GitHub ってとこに全部あります。MNIST という手書き文字を使った分類を例題として、ざっくり作業手順について説明している模様。パラメータの調整には あんまり関係ないですが、一応、流れを確認しておきます。
パラメーターに直接 関係すると思われる文献は以下の文章中のリンクです。
For tips on improving the performance and results of your Deep Learning model, refer to our Definintive Performance Tuning Guide for Deep Learning.
このページに 長々と 「どうしたらこうなった」 という記事が書かれています。実際のサンプルをもとに説明がされていて、読者もおなじものをダウンロードして確認できるようになっている模様です。ちょっとしんどい。
ベンチマークに関する記述が主な内容かも。分析にかかった時間と精度に関する内容が主ですね。どれだけの量のデータを どれだけ走らせて、どれだけの時間がかかって どれくらいの精度が得られたか? みたいな。ちなみにCPUに関する記述もありました。
パラメーターに関する知識は別のところで学習するしかないかもしれません。勉強不足で申し訳ありません。
個別パラメーター名をキーワードとして、海外の学術論文を検索して知識を得るのがもっとも正確に知る方法かと思います。ハードルはちょっと高いですけど、やってみる価値はあると思います。
あとは 自分でとにかく使ってみて、経験的に良い調整をつかんでいくとか。回帰にしろ分類にしろ予測精度が高くなればいいだけの話なので、あらかじめ知見が得られている事象でテストを繰り返せば、それなりの結論は得られると思うのです。
上のデータサイエンスアルゴリズムというページ。 ここにはH2Oでできるアルゴリズム すべてについての記述があります。ディープラーニングについては ずーっとスクロールして下のほうにあります。
目次で飛べるようにはなっていないので、面倒ですが下まで下げながら探してください。
ディープラーニングは非常にたくさんの項目があります。そのそれぞれについて簡単な説明がされています。ただし具体的調整についての記述はないです。
と、ここまで書いて・・・すべてまとめてあるページがありました!
Welcome to H2O 3.0
このページだけですごいヴォリュームがあります。すべて1ページに書かれています。左側のメニューや、本文中のリンクで目的の記事に飛べます。上であげたデータサイエンスアルゴリズムのページも左側のメニューにありますね。
いちいちスクロールしなくても ちゃんとディープラーニングにリンクが張られているようですのでご利用ください。
肝心のチューニングガイドについては、先にあげたリンクからいくしかないようです。
新しくなった H2O 実際に使ってみよう
では これから実際にダウンロードからはじめます。
New Users と書いたところから始めます。Downloads page にアクセスします。するとプラットフォームを選択する画面に移ります。僕はスタンドアロンを選びました。一番 左側のやつです。
 とりあえず どこでもいいので保存します。解凍はしておいてください。
とりあえず どこでもいいので保存します。解凍はしておいてください。
次にターミナルからアクセスします。
上のページにも簡単なアクセス方法が示してあります。

要するに 解凍された h2o-3.8.0.2 を カレントディレクトリ(ウェブ上の作業場)として、java で jarファイルを開けばいいだけです。
以下のようにコマンドプロンプトで h2o-3.8.0.2 のファイル場所を指定して java -jar h2o.jar と書いてやればOKです。
cd h2o-3.8.0.2
java -jar h2o.jar
ENTER を押してズラズラ~とコマンドが動けば成功です。
ファイルにアクセスできたら次にブラウザを開きます。
黄色で囲まれたアドレス http://localhost:54321
ここにアクセスすればOKです。ファイルにアクセスできていない状態でアドレスを開いても上手くいきません。ちゃんとカレントディレクトリを変更してからアクセスしてください。
下のような画面が出ます。ここで すべて H2Oを使った作業ができます。
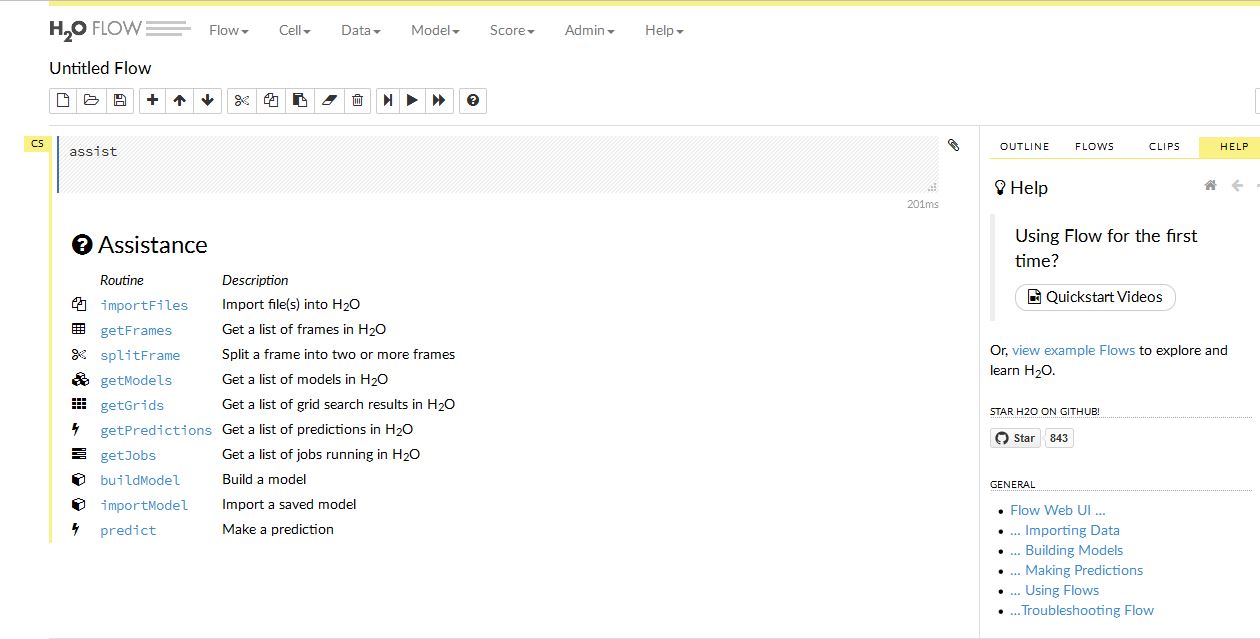
以前のヴァージョンは ブルーが基調の画面でしたが、今回は真っ白になってます。いろいろメニューがあって 何をいじればいいのか 戸惑いますが、基本は同じようです。
アクセスに使ったコマンドプロンプトを閉じてしまうとブラウザ上のH2Oもアクセス不能になります。使用中は付けっぱなしにしておいてください。
だいたいの作業の流れは データを入力して、モデルを選択、そして結果を出力する という単純なものです。
今回はここまで。また追記します。
H2O ダウンロードはできたが何をしていいか分からない方への提案
H2O はすべてが英語で書かれています。このセクションでは大まかな作業の流れについて書きます。
H2O にアクセスしてページを開くと、それ以後の すべての作業 が、そのページに記録されていき画面が縦に長くなっていきます。作業を最初からやり直したいときは、下の画像を参考にページを新しくしてください。
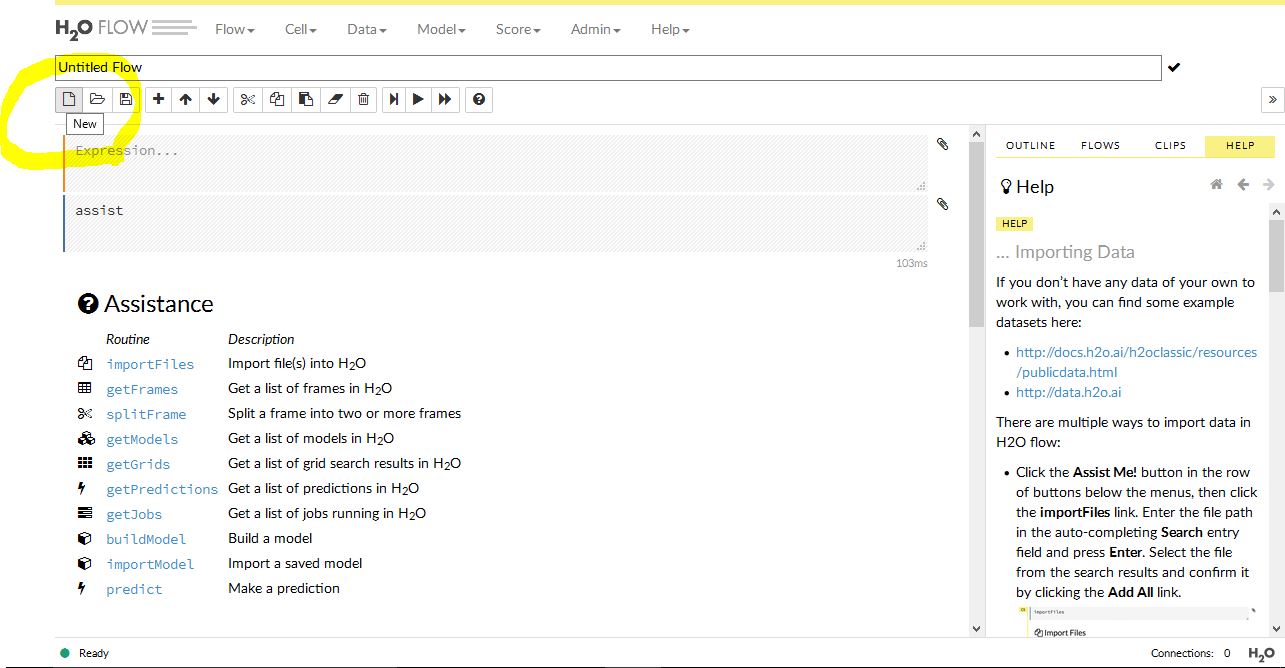
コンティニューの確認が表示されますので Create New Notebook を選択。これで画面が初期化されます。他にも一番上の FLOW タブで NEW FLOW を選択すれば画面がクリアされます。
ではまずデータから。
どんなデータを与えればいいのか? 参考サイトのデータからヒントを得る。
最初にH2Oにアクセスすると、下に表示した画面が出ると思います。
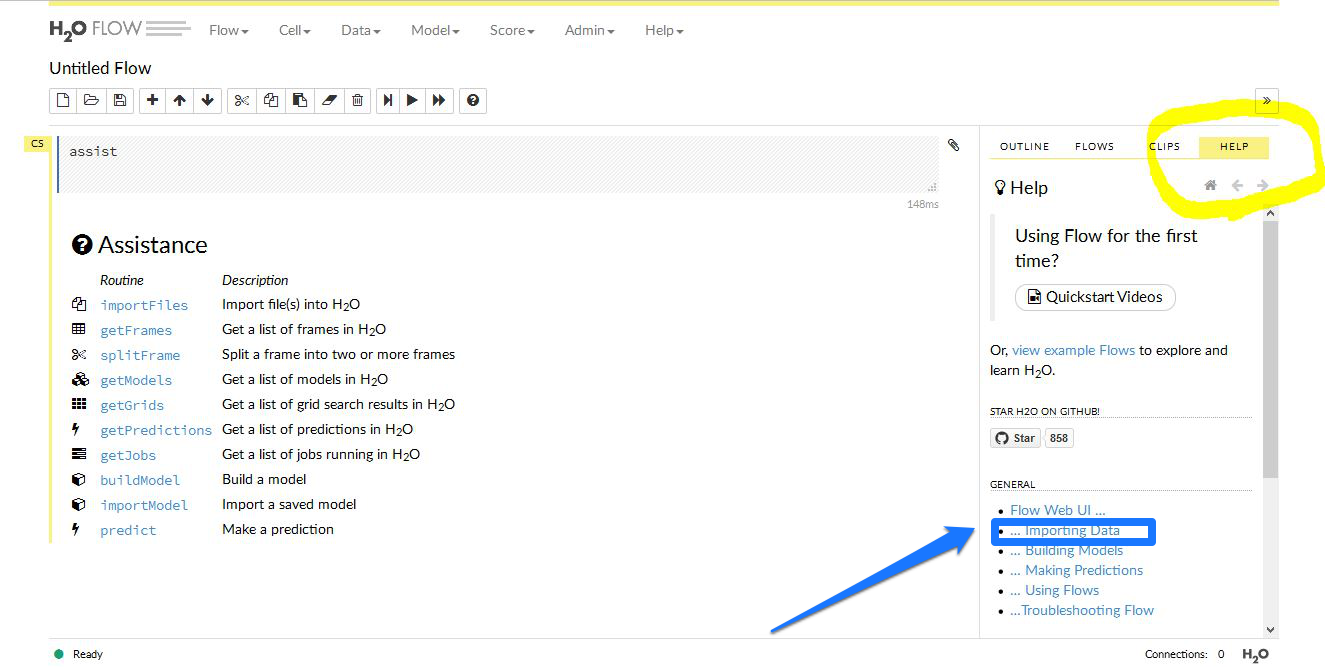 画面右側にHELPが出ています。青矢印で示した importing data をクリックします。ヘルプ画面が変わります。ここには H2O へのデータの与え方について書かれています。
画面右側にHELPが出ています。青矢印で示した importing data をクリックします。ヘルプ画面が変わります。ここには H2O へのデータの与え方について書かれています。
まだ自分でデータを持っていない場合や、与えるデータ構造についてヒントを得たい場合は下のリンクからデータを探して使うことができます。
H2Oでは あらかじめデータをローカルで、自分のパソコン内に保存しておく必要があります。インポート作業はデータを用意してからとなります。
スクレイピング技術で関心のあるデータを獲りにいく。
どうせやるなら 自分の関心のあるテーマでデータを用意したほうがいいです。チュートリアルなんかやったって面白くないし、役にも立ちません。
まずデータの形式はCSVでよいと思います。なぜなら前のバージョンでもCSV形式ファイルで上手く機能したからです。中身は 何かについて、その属性をズラズラと並べたもの でいい。
スクレイピングといっても技術的に難しいものは扱いません。もっと簡単にできるものを使います。たとえば以下のようなものです。

もうひとつは kimono

kimono のほうは 自動的に追跡してくれる機能も説明されているので役に立ちそうですね。とりあえずは以上二つを使えばデータは獲れると思います。手作業でまとめると気が遠くなりますので、こういった 半自動でデータを集めてまとめる効率的な方法 についての知識を増やしていかなければなりません。
データ構成について
データに関しては 統計解析ソフト R の考え方 を参照するとよいです。

各行が各事例の観測値となっていて、各列に属性値がずらっと並ぶ形です。形に関してはこのページで理解できるはずです。
まず、目的変数を決め、次に 関係する説明変数を考えます。
通常の予測では 相関係数 や、あるいは これまでの知見から得られた結果から説明変数を種々選択して予測モデルをつくります。
この 説明変数の取り方 というのが、いわゆる フューチャーエンジニアリング 特徴選択工学 と呼ばれるものです。

ウィキの情報が古いのかディープラーニングについては触れられていません。私の理解が正しければ以下のようになります。
ディープラーニングの肝は、一般にフィルタリングといわれているようなもの、データクリーニング といわれている作業 つまり人間が自分の知見にもとづいてデータを整形する作業を、機械みずからがデータの特徴を学習することで行うことにある。
というわけで、データの属性項目に関しては できるだけ集める という方向で考えればいいと思う。独断で ある属性 を排除してしまうのは 予測可能性 の幅を狭めることになるんじゃないか? と思います。
何を対象とするか? 何を予測したいと考えるのか? これによってデータの作り方は大きく変わる。
僕の場合、やっぱりやってて楽しいのは ギャンブル関連です。スポーツの勝敗予想とか。世間的に関心の高いのは株価とか為替変動の予測。競馬も関心が高いですね。進んでいる分野としては金融の世界。例として最近のニュースを取り上げてみます。
こういった例をみると、個人ではもう到底太刀打ちできないような気がします。アメリカなどの最先端では何が行われているか想像すらつきません。話はそれましたが、何を予測するか でデータの作り方はいろいろあります。

株や為替の値動きを 画像 として分類予測させている個人の方もいるようです。私の過去記事にある LABELLIO についての記事 もその一環として考えてもらっていいです。(全然進んでいませんが。。)
興味深いです。”ディープラーニング” と 何かのキーワードを組み合わせれば 金融分野だけではなく、いろんな事例が検索でヒットするはずです。こういったところからもヒントは得ることができます。もうひとつ、考え方で参考になる記事を紹介しておきます。


まさに僕の言いたいことが書いてあります。
ディープラーニングにはグーグルが無償提供しているテンソルフローや日本人発のChainerとか、いろんなものがあります。そして、いずれもが 手書き文字 による分類問題を ”HELLO WORLD” としてチュートリアルで扱っています。このH2Oだってそうです。
しかし僕には無意味。こんな分類問題をやったところで未来予測とは直接結びつきません。あくまで特徴量抽出という点で有効であるということしか分からない。
それが何であるか? を判別するだけのことです。そうではなくて もっと動的な事象を予測する。ある条件(変数)の時にどういう動きをするか? どれくらいの可能性があるか? そういった人間の判断を助けるような学習を機械にさせて活用することをしたい。
予測することと分類問題は違う。回帰のほうが予測に近い。ディープラーニングでは たくさんのチュートリアル関連の資料はあるけれど、未来予測らしい活用方法について詳しく書いてある文献を探したほうが良いです。
H2O データのインポートの方法 データの読み込ませについて。日本語によるデータを文字化けさせずに読み込ませる。
まず日本語で書かれたデータを用意します。いや、べつに日本語でなくても構いません。半角英数で記入されたデータならちゃんと認識できるはず。文字化けが起こるのは、日本語で、しかもエクセルを使ったデータなら・・という場合です。このケースでは必ず文字化けします。文字コードを UTF-8 にすれば日本語で表示されます。
以下のグレー囲み記述内容は 旧ヴァージョン対応のやり方です。H2O-3 は、新ヴァージョン対応を参考にしてください。
アップロード直後はUTF-8でも文字化けしています。これはパースするとちゃんと日本語で表示されるようになります。
解決方法は検索でいろいろヒットします。僕がやる方法は データの読み込ませについて で解説してありますので参照してください。
日本語データの文字化けを正常に表示させる方法 新ヴァージョン対応
自作データを使って、いろいろ試してみた結果 正常に表示されるようになったので その過程を記録しておきます。環境が違うかもしれませんので、あくまで参考資料としてお読みください。
1、エクセルを使って日本語でデータを作ります。日本語と半角英数などが混在しても構いません。あと記号などもOKです。
2、上で作成したデータを丸ごとコピーします。コピーしたデータを TeraPad というテキストエディタに新規ファイルとしてペーストします。
3、文字コードを UTF-8N で保存します。UTF-8 では上手くいきません。拡張子は CSV です。 ファイル名.csv という形になります。
これで 読み込ませてパースすると 属性名 データ本体 とも正常に読めるようになりました。以下に画像とともに注意点を挙げておきます。
元データはこんな感じ。エクセルの一番上段に属性名が並べてあります。各列ごとにデータ本体が並べてあります。データ本体は2行目からになります。
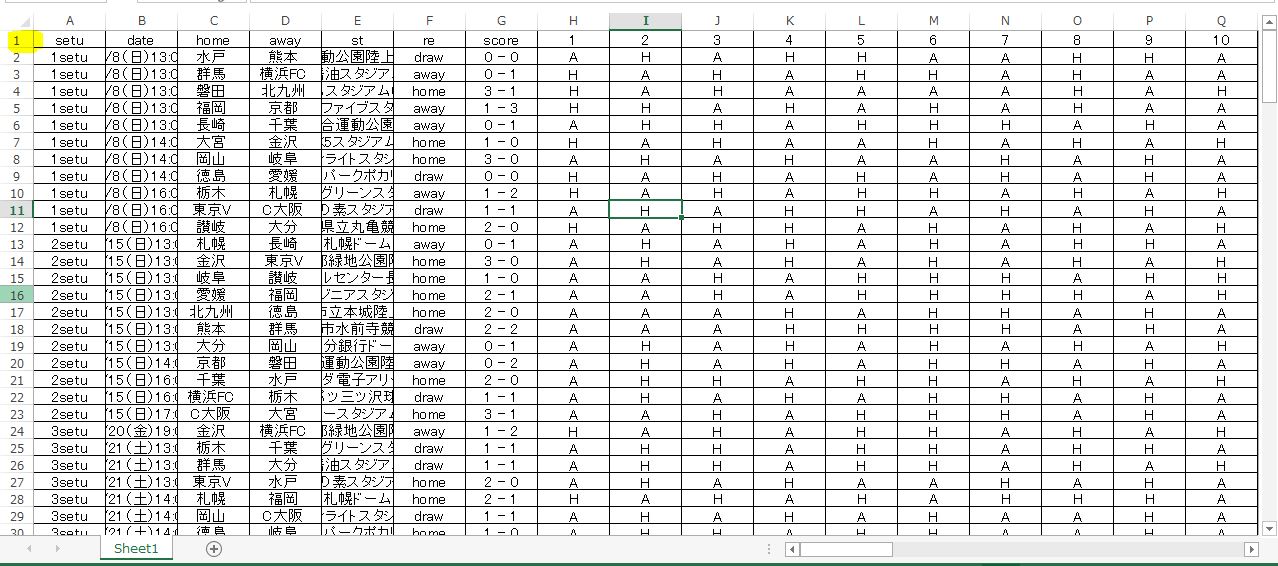
下は丸ごとコピーしたデータをTeraPadに貼り付けて、保存しているところ。TeraPad は、文字コード UTF-8N が選択できるので、これをメニューから選んで 名前を付けて保存します。とりあえず拡張子は CSV にします。他のもの たとえば XLS でも読み込めるみたいですが、CSVで上手くいったので間違いないと思います。
下は データをアップロードしたところ。この時点ではまだ文字化けしています。これは正常な状態ですので勘違いしないように。
読み込みができると、自動的にパーサーとセパレーターが選択されます。これはいじらなくてもよいようです。注意するのは黄色で囲んだところ。カラムヘッダーの有無についてです。これは1段目に属性名があるかどうかを選択するものです。データの一番上に名前が付けられているなら真ん中を選んでください。もし、なにもなければ First row contains data を選んでください。
AUTO では上手く機能しませんでした。
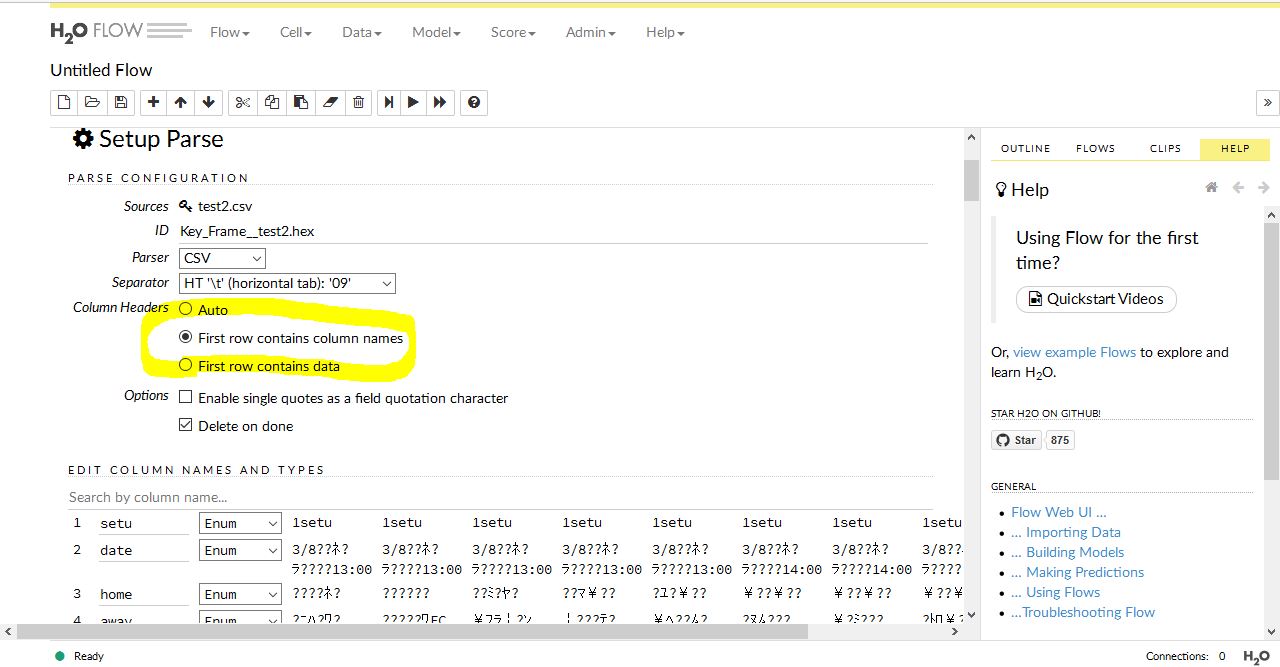
設定が完了したら Parse を押します。すると薄いグレーの parseFiles のあとに次の Job という画面が出ます。

黄色で囲まれた View を押すと アクションを選択できるようになります。
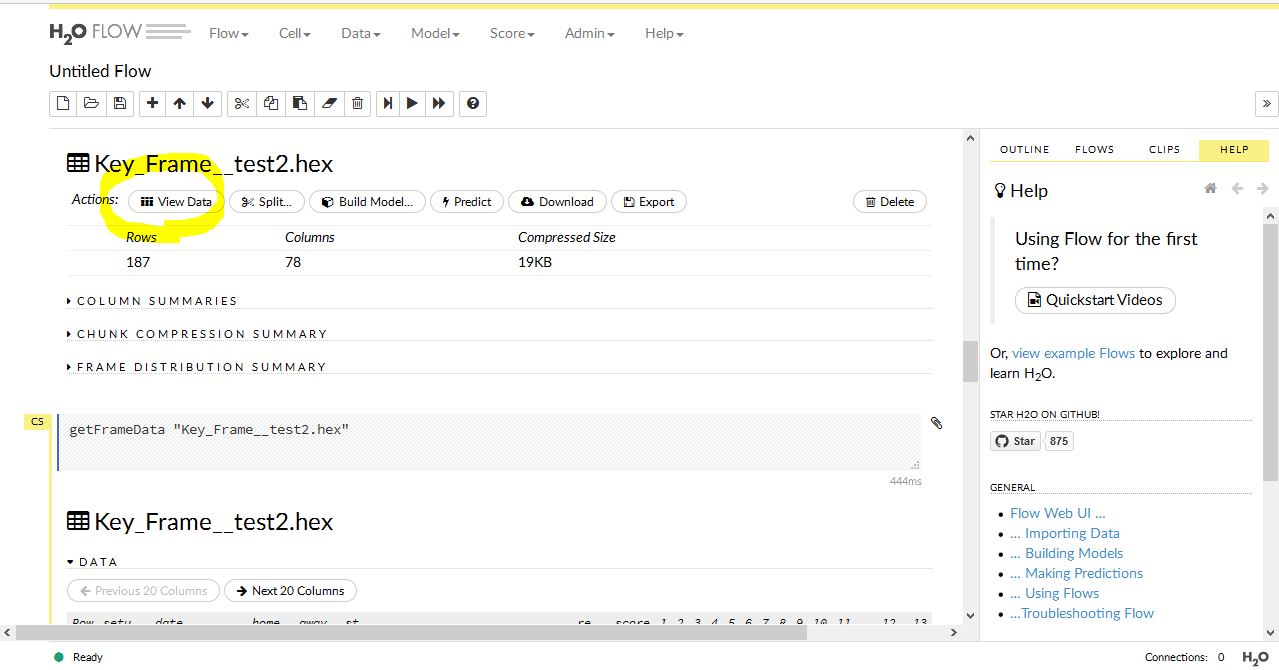 上の黄色はデータを確認するボタンです。その並びに モデル作成 やら、予測、データのダウンロード や、Export などがあります。 スプリット というのは、おそらく予測精度の検証に使うためにデータを分割するためのものだと思います。
上の黄色はデータを確認するボタンです。その並びに モデル作成 やら、予測、データのダウンロード や、Export などがあります。 スプリット というのは、おそらく予測精度の検証に使うためにデータを分割するためのものだと思います。
以下の画像は今回の自作データの確認画像です。
データ本体は ちゃんと 1 から始まっています。一番上には属性名が示されています。これでやっと正常表示されました。
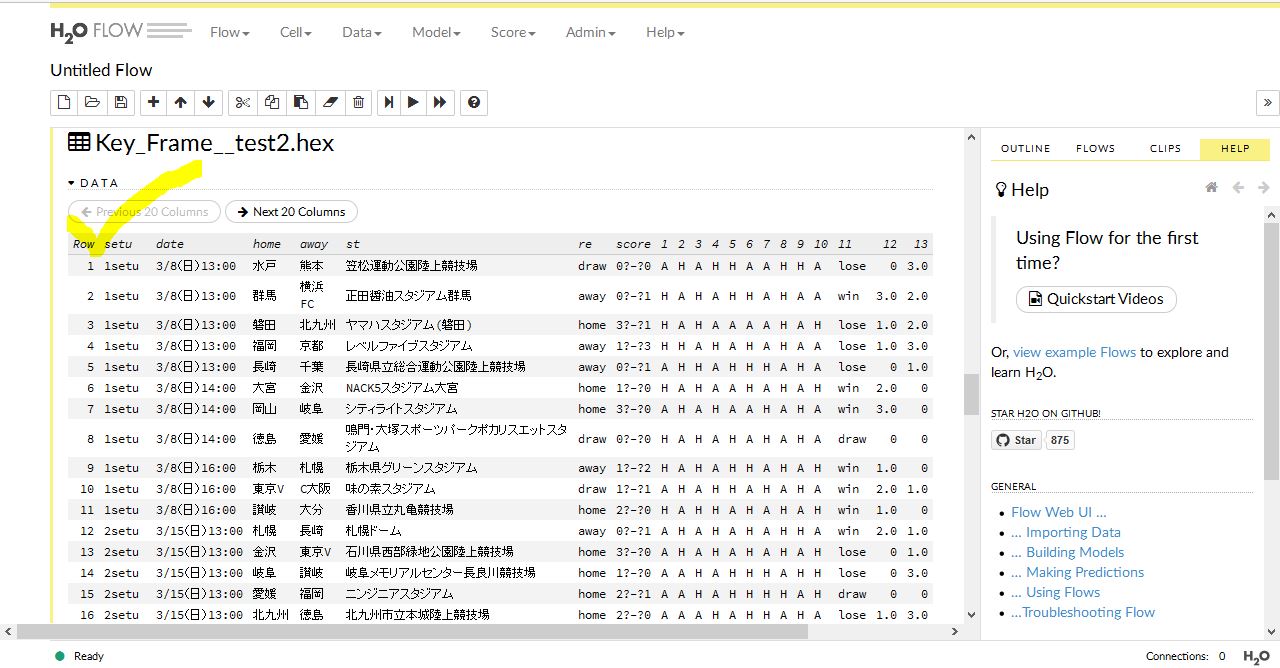
以前のヴァージョンでは、UTF-8 で正常表示されたんですが、今回は、なかなか表示されませんでした。行がくずれたり、カラムヘッダーがおかしな表示になったりして困っていました。なぜUTF-8Nで治ったのか 理由は分かりません。とにかく上手くいったということで良しとします。
CSVデータの保存時における名前は日本語を使ってはいけません。エラーになるようです。また属性名は英数字を使った方が良いです。
UTF-8N で保存されたCSVデータの名前の付け方です。
英数字.csv という形にしてください。
ここを漢字など日本語にするとエラーになって読み込みしてくれません。
データ本体の文字化けは パースをしたあとに日本語や記号が正常に表示されるようになります。しかし日本語で書かれた属性名の文字化けは 読み込みをした後にパースしても直りません。対処方法は パースする前に エディット で修正します。
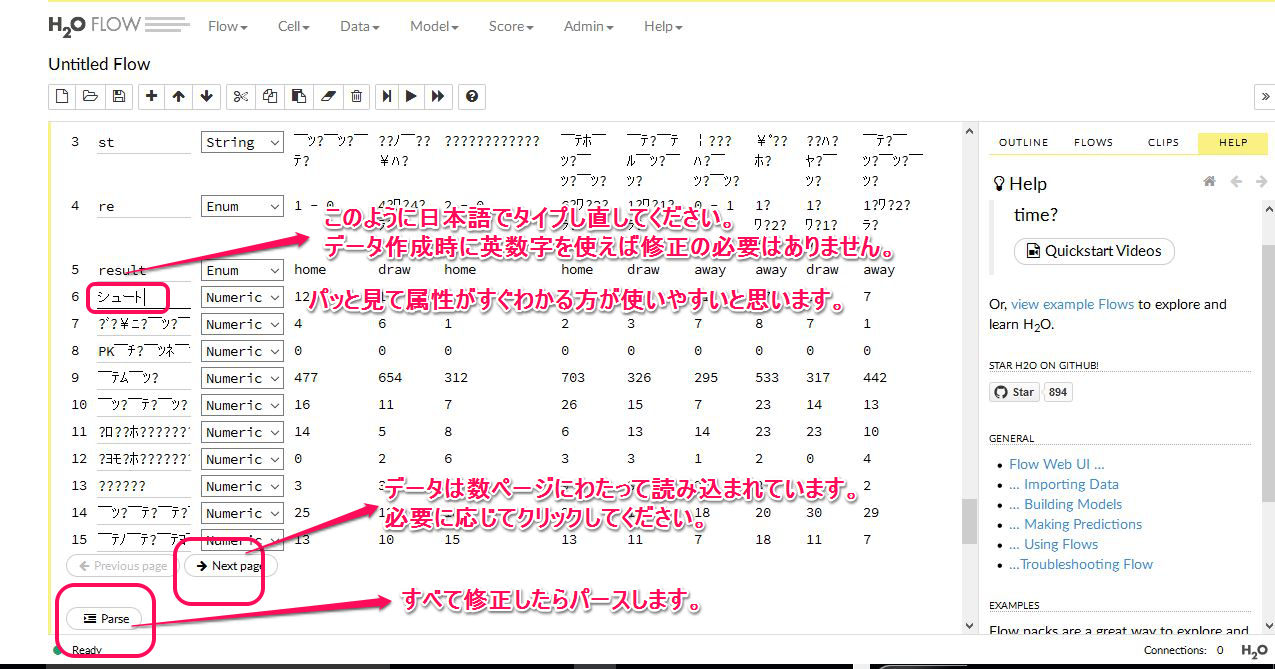
以上、ちょっとややこしいので もう一度整理します。
実際にデータを読み込ませる方法は二つあります。
そこでアップロードを指定すると参照ウィンドウが開くのでファイルを指定すればOKです。インポートの場合は、ファイルのあるフォルダをパス名で指定すれば中身が表示されます。パス名はまずフォルダのプロパティを開き、場所を見ればコピーできます。
パス名を入力してサーチボタンで結果が表示されます。
アップロードとローカルフォルダを指定してやるやり方、どちらも結局は同じです。ファイルがどこにあるか分かっているなら単純にアップロードでいいし、分からないならフォルダを指定すればズラズラと表示されるので、そこから Add すればいいだけです。
あとは パースボタン があるので これを押す。すると読み込みが開始され、結果が表示されます。ここでちゃんと属性数と行数が元のデータと合っていれば正常に読み込みがされているはずです。
最初に学習データを与えて モデル を作成するわけです。この時点で交差検定などいろいろテストをして最終的な 予測モデル、分類モデルをつくります。
ディープラーニングを使った予測モデルの構築 グリッドサーチを使ってパラメーターを自動調整する
まだ試作の段階ですが、グリッドサーチ機能を使って予測モデルを構築してみます。必要なデータは2種類、モデル構築用データと検証用データです。
作業工程を整理します。
- まず2種類のデータを用意する
ふたつ同時にアップロードする。別々でも構わない。インポート機能で複数のファイルをアップロードするとファイルが結合することが判明。別々にアップロードしてください。- ふたつともパースする。
- モデル構築用と検証用それぞれの H2Oにおけるファイル名 を所定の欄に記入(パースすると自動的にファイル名が付けられる)
- 実行
ちょっと勘違いをしていたので訂正します。
ここで述べている方法はグリッドサーチではありませんでした。トレーニングデータを使ってモデル構築を行う際に、トレーニングデータを使わないで クロスヴァリデーション を行うやり方です。
通常は トレーニングデータの一部分を使って 交差検定 をします。それをまったく別のデータで検証するだけの話です。申し訳ありませんでした。
グリッドサーチ機能を使ったモデル構築については新しい記事を予定しています。


コメント