
この記事ではH2Oを使った具体的な予測作業の流れについて、備忘録を兼ねて記録します。予測モデル精度の向上手法についてはあまり触れないでおきます。そういったモデル検証については項を改めて研究したいと思います。機械学習の予測性能向上については情報は多いです。
ここでは単純に データの書き方 や、与え方、そして 次はどうするの? という感じで書きます。上級者の方には参考にならないです。これからダウンロードして初めてH2Oに触れる方の参考になればと思います。
予測モデル作成後にどうやって未知のデータについて予測させるのか? その具体的手法についての記録
機械学習というと必ず クロスバリデーション 交差検定 という言葉が出てきます。これはモデルの性能を検証するためには必ず行わなければならないものです。しかし、いくら予測モデルの性能が高くなっても 未知のものに対する予測結果の正確性を担保するものではないことは頭に入れておくべきです。
たいていの予測メソッドは、この性能向上に関する記事ばっかりで、肝心の具体的予測手法をわかりやすく解説しているものはないような気がします。H2Oも例外ではなくて、ヘルプを見ても、モデル作成後に いったいどうすればいいのか? についてはあまり詳しく書かれてはいません。
僕もいろいろ試行しながら、やっとやり方が分かったので記録に残しておこうと思いました。英語がスラスラと理解できるならば、もっと簡単に理解できたかもしれません。
話をディープラーニングを使った分類モデルに限定して進めます。
H2O ディープラーニング 結果の分かっている教師データで予測モデルをつくり、そのモデルでデータから分類項目を予測するやり方
僕がやろうとしていることは、”データとその分類結果が分かっている” というファイルを元にして予測モデルをまず作成するということ。次にその予測モデルを使って、未知のデータを分類することです。具体的にはまず予測モデル作成用に下のようなファイルを用意しました。いわゆる教師付きデータです。(ラベリングされたデータ)
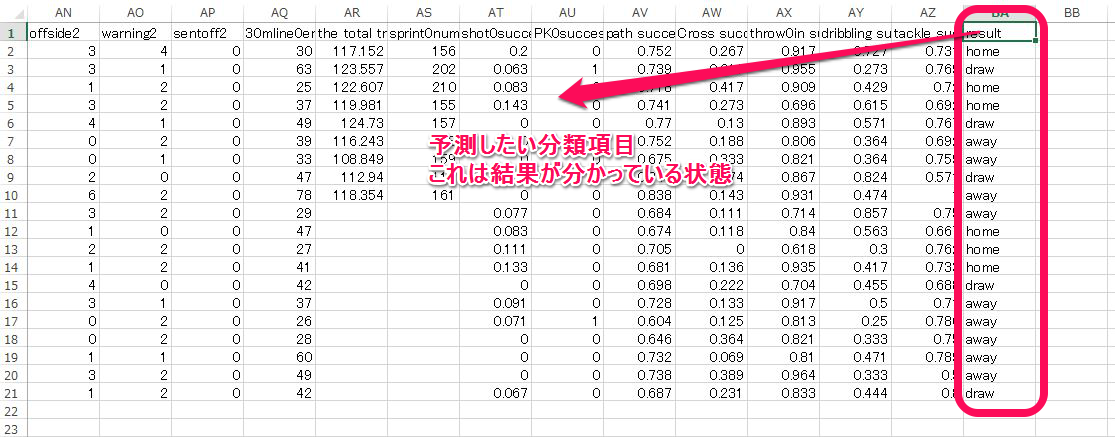
これを読み込ませます。そしてパースしておきます。パースされたデータはH2Oに記憶され、いつでも呼び出して使えるようになります。
モデル作成は後回しにして、次は予測用データをおなじようにアップロードしてパースします。具体的データ形式は以下です。
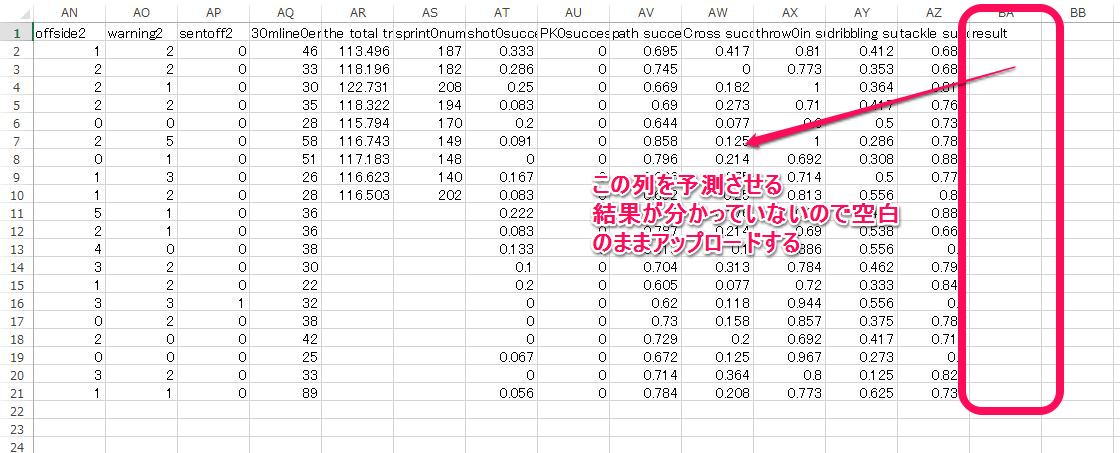
これでモデル作成用と予測用データのふたつがH20に記憶されました。次に予測モデルを構築します。使うデータは最初に挙げた教師付きデータです。これを呼び出して 作業します。記憶されたデータの確認は以下のように行います。
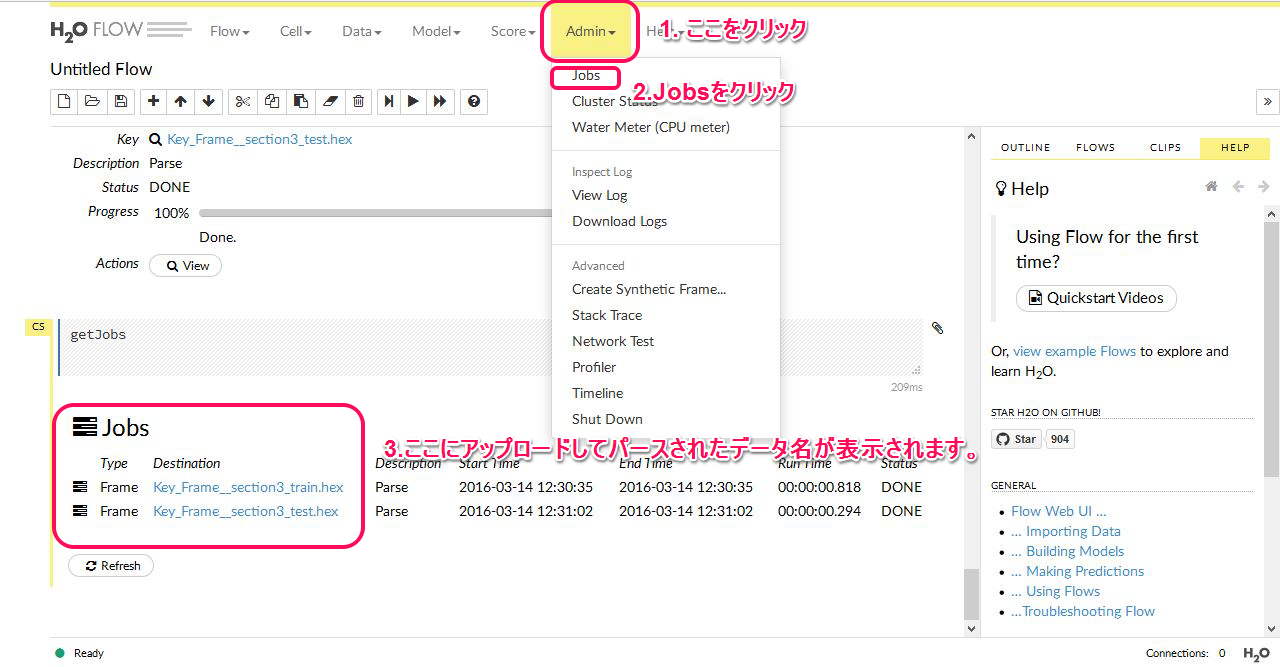
次に予測モデルを構築します。選択方法は以下です。
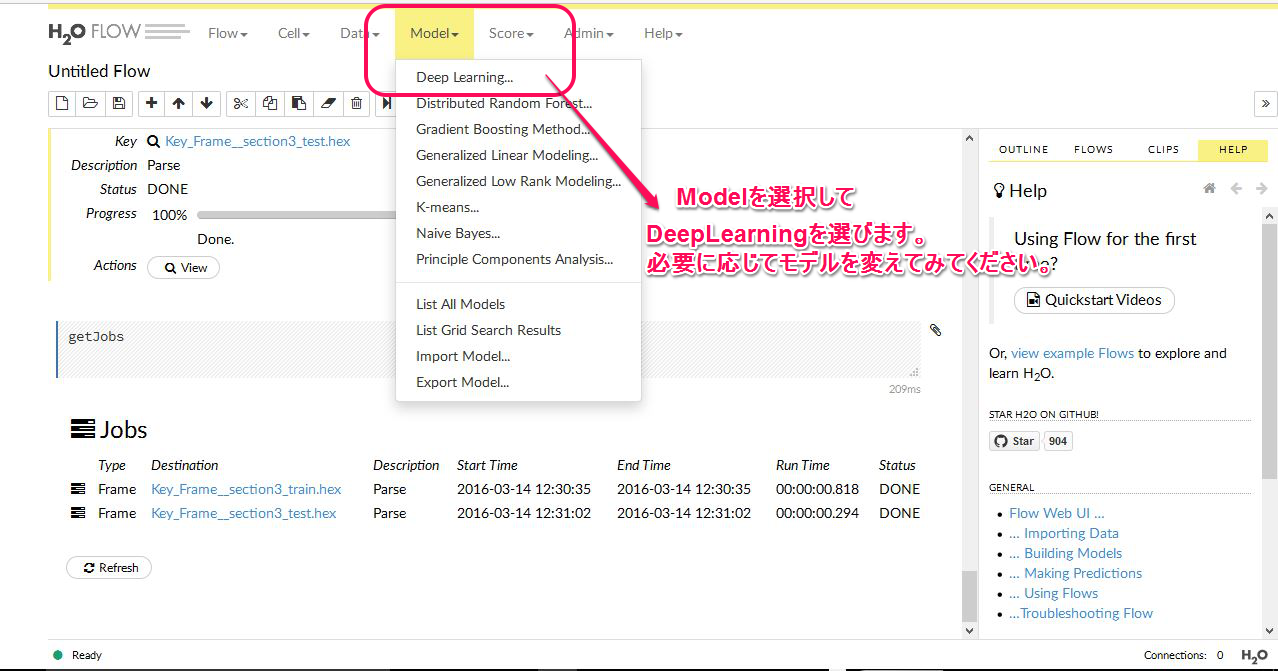
モデルにディープラーニングを選ぶと以下のような画面になります。ここでは性能アップのためのクロスバリデーションについては触れません。とにかくモデル構築だけに専念します。
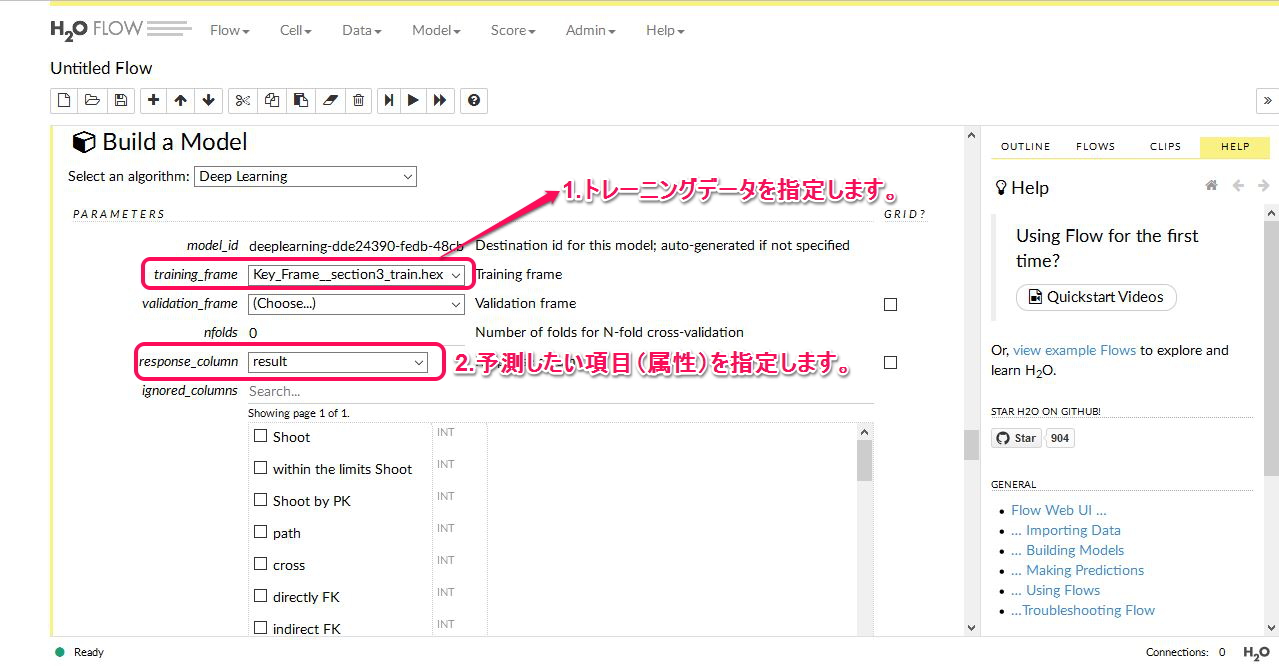
まずトレーニングデータを入力します。入力方式は入力欄右側 ∨ をクリックします。するとデータ名が表示されますので、そこから予測モデル作成用としてアップロードしたファイルを選択します。具体的には教師付きデータ(ラベリングされたデータ)を選択します。
次に レスポンスカラム を指定します。この場合では result となります。つまり予測用データで空白にしたカラムを指定します。
あとの細々した設定は今は無視してください。画面をスクロールすると一番最後に Build a Model というボタンがありますので それを押してください。以下の画像はモデル構築終了後のものです。
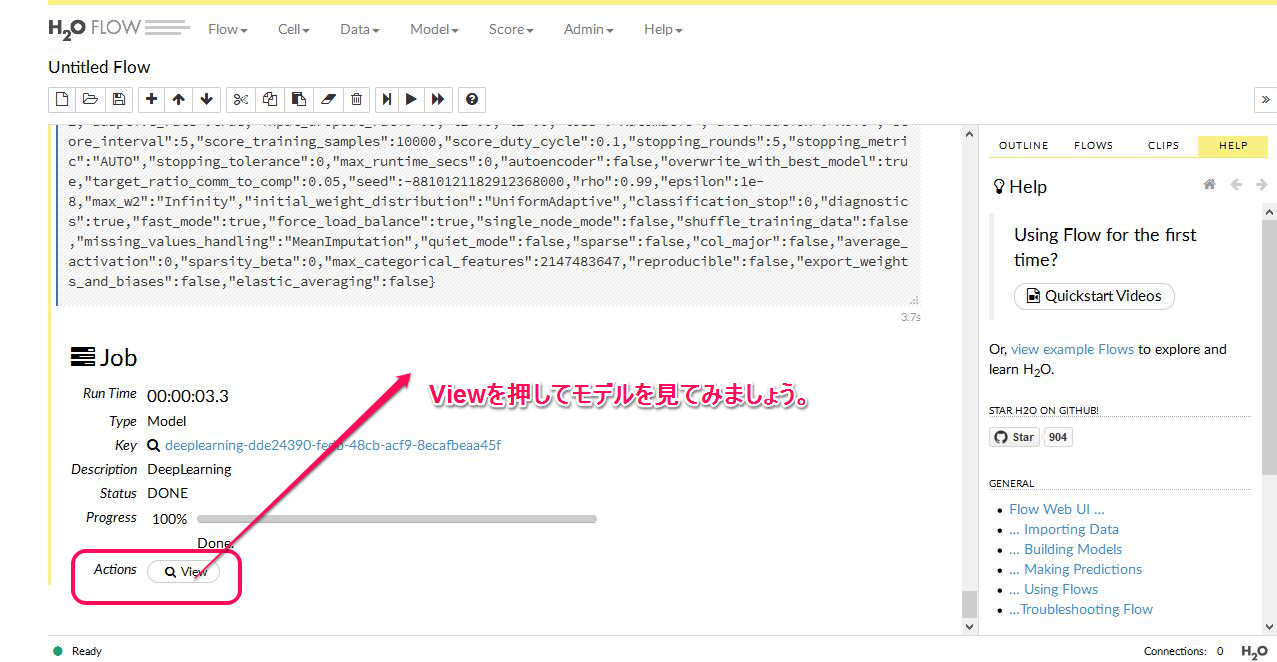
次にモデルのACTIONタブからPREDICTを選んでクリックします。
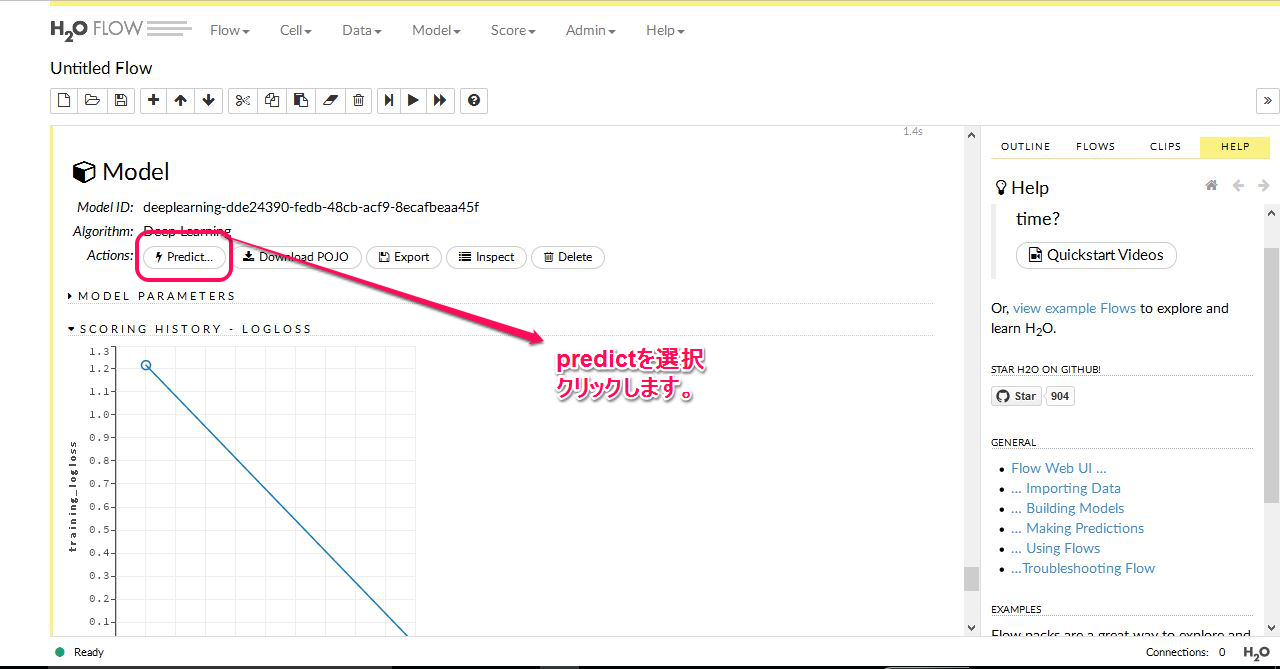
下のような画面になります。ここではFRAMEを選択します。具体的には ”アップロードされた分類がまだ予測されていないデータ名” をここに入力します。タブから選択します。選択したらアクションボタンを押します。
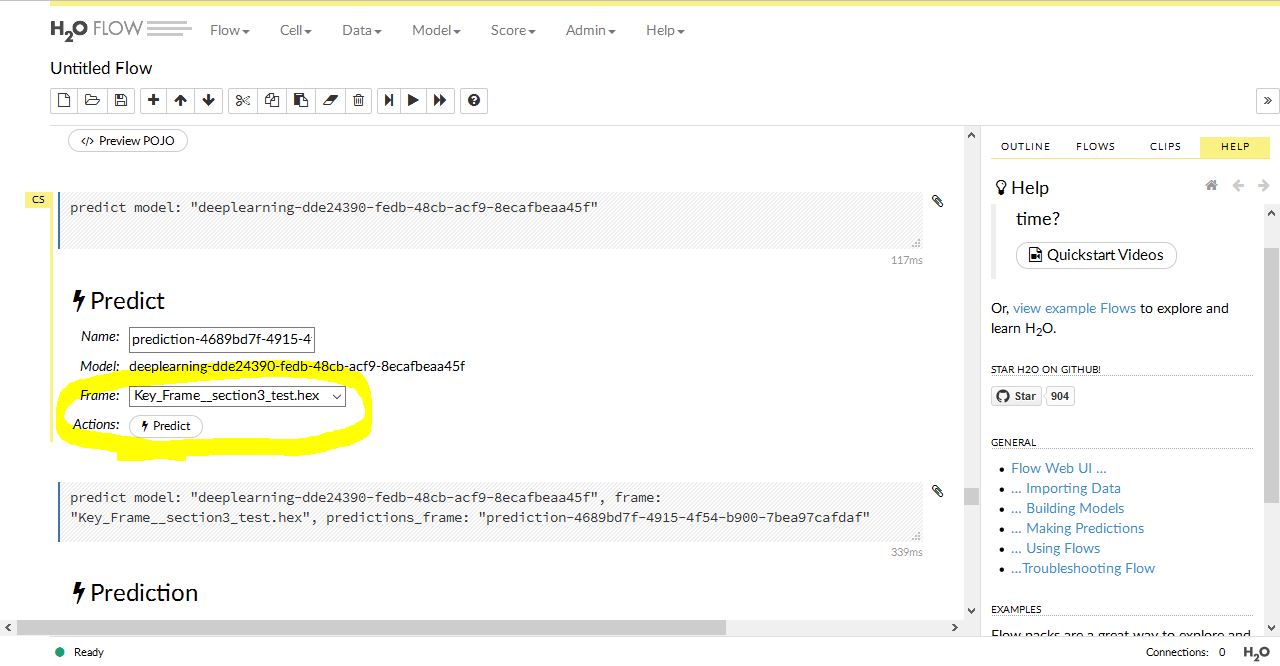
次は Prediction という画面になります。ここでは上の作業の結果が示されていますが、目的変数の欄が空白でしたので結果も NaN となっています。
そこで作成された予測モデルと ”これから予測したいデータ” を結合させる作業をします。

上の画像の黄色枠に注目してください。ここに Combining Prediction with Frame とあります。ここをクリックします。すると以下のような表示がでます。これは結合(予測)が上手くできたことを示しています。
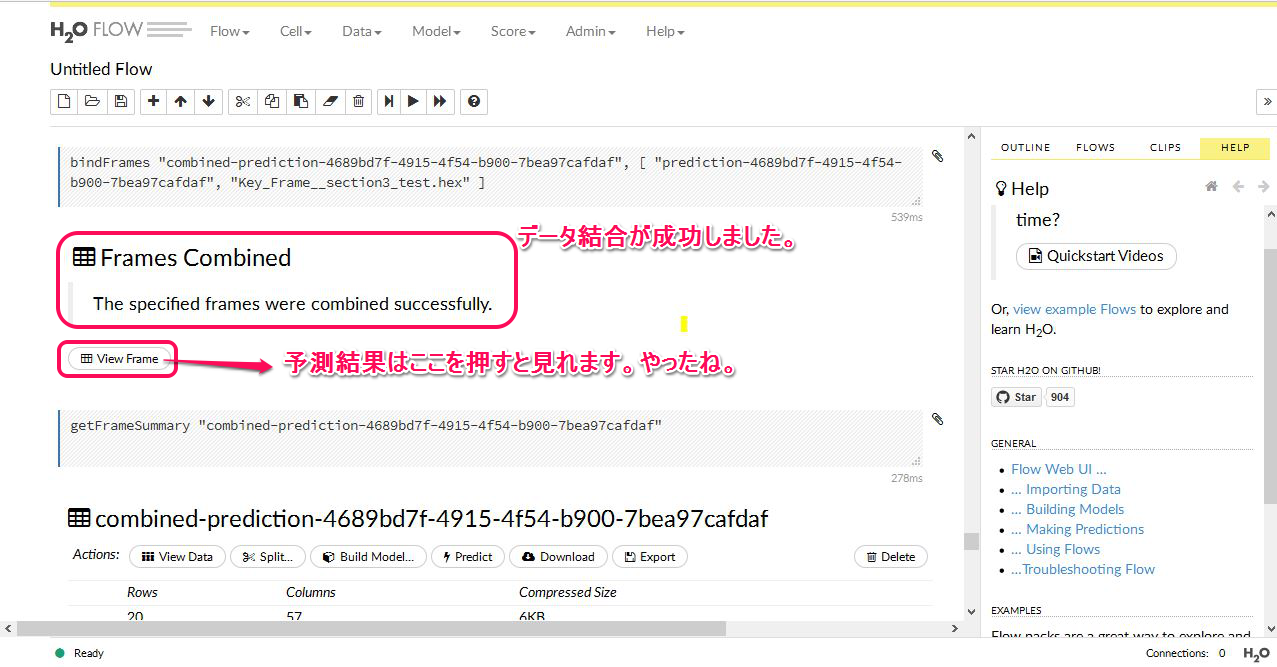
では実際にちゃんと予測されているか確認してみましょう。上の画像のヴューフレームボタンを押すと、まず表示されるのが Column Summaries です。以下のような表。
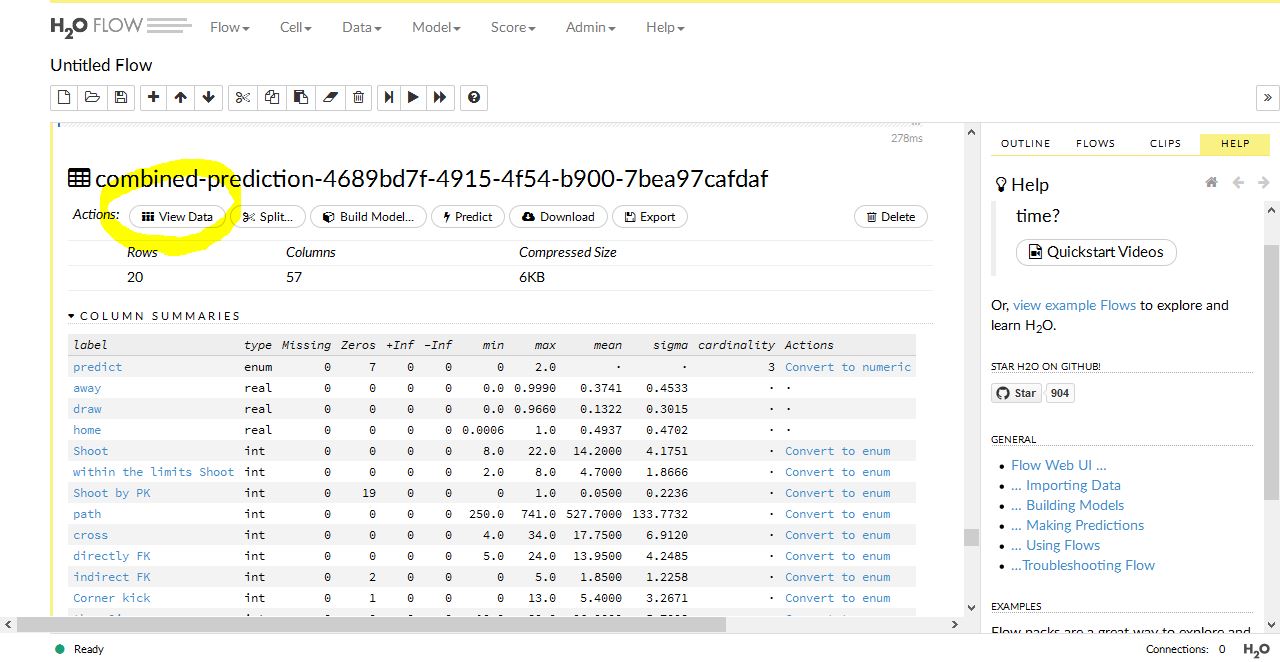 これはちょっと見方が分からないのですが、肝心の 未知の分類結果 はどうなったかというと・・・上の画像の View Data をクリックします。すると・・・
これはちょっと見方が分からないのですが、肝心の 未知の分類結果 はどうなったかというと・・・上の画像の View Data をクリックします。すると・・・
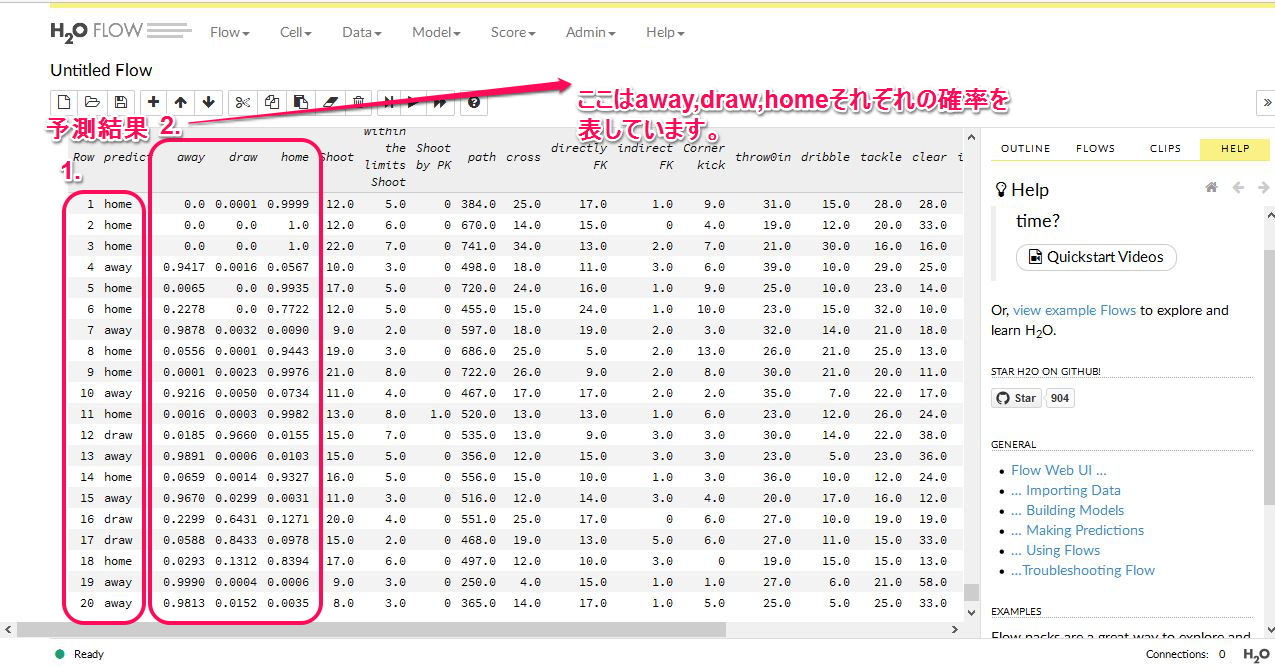
ちゃんと予測モデルにしたがって予測結果が出力されました。データ本体の中身の数値も確認しましたので間違いなく予測結果が出力されています。予測結果の正確性については全然納得がいっていませんが、それはモデルの性能をあげる工夫をすればいいだけのこと。
今回はH2Oを使った予測モデルの構築と、そのモデルを使った予測の流れについて解説してみました。ほかに効率的な良い手法があるのかもしれません。
具体的手法が分かったところで、つぎはモデルの精度をいかにして上げるか? そういうことになってきます。
新たなことが分かり次第 随時更新予定です。

コメント