
過去データをどれくらい遡ってトレーニングデータとするか?
トト予想に機械学習を使う場合、問題となるのは 「どんな過去データを教師データとするか?」 ともうひとつ、「どれくらいのデータ量が必要なのか?」 というふたつの問いに直面すると思います。
正直いってこれらの問いにどう答えをだせばいいのか、僕にはさっぱり分からない。どれだけテストを繰り返してもキリがないように思える。まあ、精一杯やってみてベストをつくしかないだろうと思います。
今回はひとつのテストケースとして、僕なりの結果を示してみたい。やり方は単純です。以下にテスト手順と予測結果を載せてみます。対象は J2第5節 です。
テストケース1、対戦カードとそのスコアだけを使って予測する。
具体的なトレーニングデータは以下のようなものです。
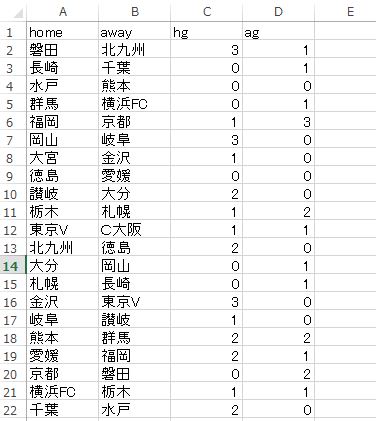
すごくシンプルで、対戦組み合わせとそのスコアを分解したものだけです。これを2015、2016の二年分と、そして今季2017の第4節までをトレーニングデータとします。
テストデータとしては、J2 第5節の対戦カードを、上と同じフォーマットで別ファイルとして作ります。以下のようになります。
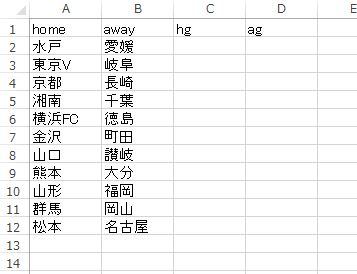
空欄となっている hg,ag それぞれを予測するわけです。
H2O ai に読み込みさせる時にはちょっと注意しなければならないことがありますが、その説明はちょっと置いておきます。
このテストケースでは、スコア情報(数字で示されているもの)は、数値として認識させてあります。したがって返されてくる結果も数値となり、その大小比較によって優劣を判断するということになります。
テスト結果を見てみる
以下がテスト結果となります。
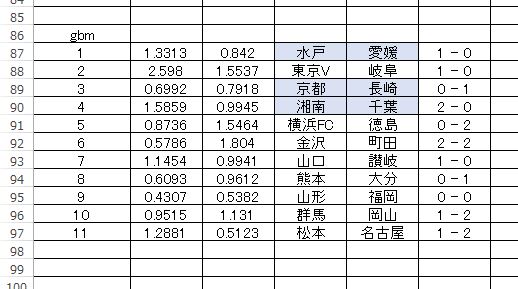
全部で3枠、間違いがありますが、全体としてはよく傾向がつかめているような気がします。この方法では引き分けを直接的に予測はできません。
ある程度データに時系列的ボリュームがあっても意外とまともな予測結果を返すんだなぁと感じます。これは意外でした。今までは過去データよりも直近データを重視していたのですが、ちょっと考えを改めたほうが良いかもしれない。
ただ、開催回によって予測ムラというのはかなりあるので、あまり信頼できるものではないと思っていた方がいいでしょうね。
最後に使用したアルゴリズムは GBM です。これを変えるとまた違った結果が得られます。やりすぎると混乱してどれを選択すればいいのか、まったく分からなくなります。困ったもんですよ。


コメント