

得点パターンと失点パターンからデータを作成する
べつに秘密にすることでもないので、自分のやったやり方を記録しておきます。

使用するデータは上のリンクから取得します。使うデータは各チームのシーズンサマリーから。ここは直近のリーグ戦が終わるたびに更新されていきます。
例として神戸の画像を貼っときます。
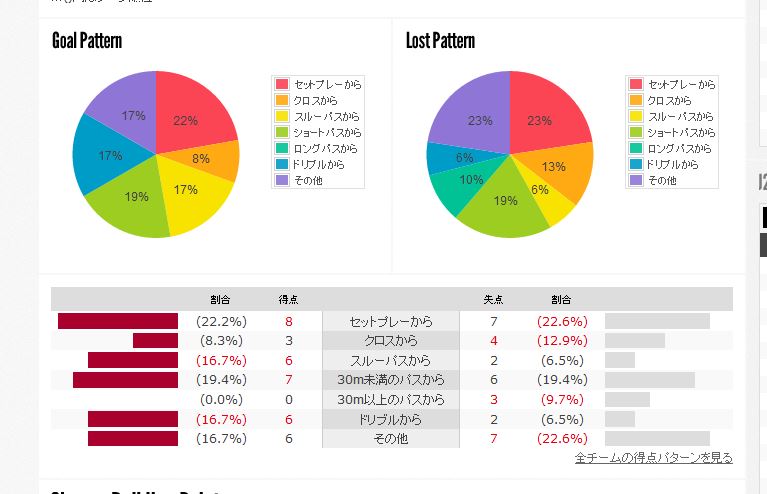
僕が使うのは下段の数値。それぞれのパターンが占める割合とゴール、および失点の実数が示されています。
今回、使用したのは実際のゴール数と失点数です。パーセントでもいいかな?とは思いましたが、パーセント表示にすると名義属性として扱われてしまうので、使いにくいと思ったからです。
ココの部分をコピペしてエクセルで整えてからデータに貼り付けます。
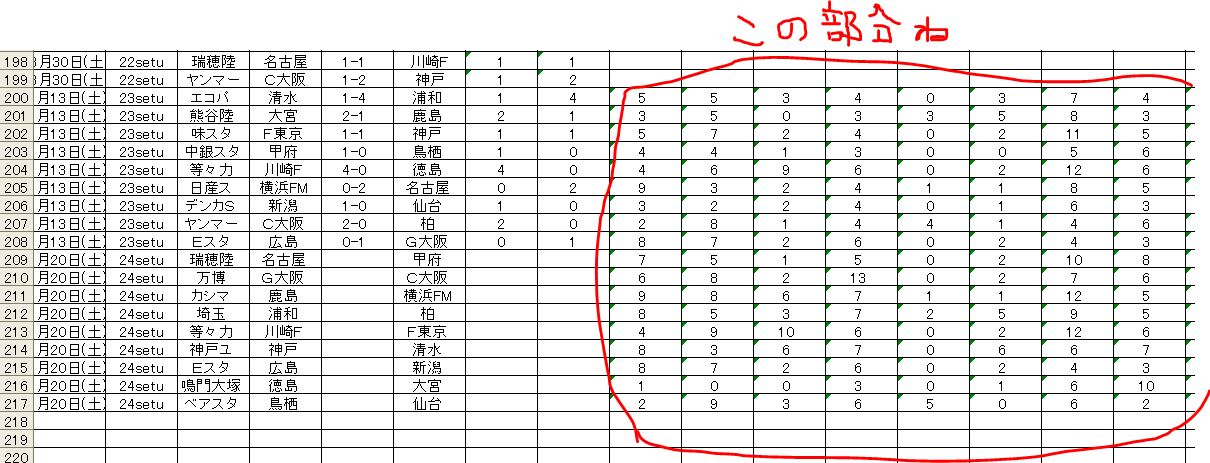
ちょっと見にくいんですが説明します。
23setu の結果の横にずらっと並べてある数字、これが22節終了時点での得失点パターンの実数です。
24setu の結果はまだ出ていませんが、おなじように実数が並べてあります。これは23節の結果を受けて更新されたデータを貼り付けています。
いずれのデータも今季の累積データです。直近のデータ(任意に区切ったデータ)ではありません。
赤線枠の左から ホームのセットプレーによる得点、クロスからの得点・・・同様に ホームのセットプレーからの失点・・・と並べてあります。これをホームとアウエイの組み合わせで並べました。1行でホームとアウエイすべての得失点パターンを並べた構成となっています。
行の一番最後列には ”目的変数” を記入しておきます。僕の場合はずばり結果 (home,draw,away)を記入しました。ここは任意でなんでもいいと思います。たとえば ”引き分けになったかどうか?” とか、ホームが勝つか、それ以外か?とかです。二択でも三択でも、あるいは4択?でもいいと思います。(分類によるパターン認識)
数字(numeric) にすれば重回帰分析になります。
作成したデータは、教師となるデータが1節分しかありません。なのでアルゴリズムを変えるとすごく出力が変化します。もっとデータを蓄積してやってみないと何も分かりませんね。
普通は ”累積の得失点数” のみに注目して予想する方は多いと思います。あるいは直近の得失点状況から考える。
これらも基本的で有効な考え方なんですが、どうしても支持率どおりというか、わりと順当な結果しか導かれないと思います。攻撃陣が好調だとかディフェンスが崩壊してるとか・・・
そこをもっと細かく人力で予想する方はたくさんいます。たとえば以下のような考え方。
このチームはセットプレーが得意
ディフェンスの裏を取られることが多い
サイドからのクロスに弱い
ドリブル突破がよい選手がいる
とか、いろいろ。サッカーブログには良い解説がたくさんあります。
「なにを数値化すればもっとも良い結果を得ることができるか?」
これは僕のサッカーにおける機械予測のテーマみたいなものなんですが、
もしかして ”得失点パターン” がそれらのロジックを数値化したものなんじゃないか?
という発想が今回のデータ化の目的でもあります。
それぞれの特徴を持ったチームがぶつかるとき、勝敗のパターンがある程度あるならば、機械的に勝敗を予測することは可能である。
サッカー勝敗は完全なランダムではありませんから。
上手くいくかな?
大まじめに書いてるので冷やかしはやめてね。
おわり。


コメント