

ディープラーニングによる画像認識技術を用いてトトくじ予想をするというアイデア
さて、現在記事タイトルにもありますように、”ディープラーニング” という機械学習を用いてトトくじの結果を予測するということにチャレンジ継続中であります。
今回の記事では、”逆転の発想” で、画像そのものを使ってトトくじの予想をするということについての話です。まだアイデア段階での妄想ですが、とりあえず忘れないうちに記録に残そうと思います。
ディープラーニングは画像認識において高い性能を発揮している
少しディープラーニング(DLと略しますね)について情報を検索すれば、
”ディープラーニングは画像認識において高い性能を発揮している”
ということは容易に理解できると思います。
DLにおいては画像データを数値データ(色彩あるいは形状の集合体)として認識しています。つまり ”属性1” は ”色彩番号が何番である” とか、”形状がどういうふうに配置されているか?” とかですね。それらをひとつずつ数値データとして認識しているんですね。
こういうように逐一細かなデータの集合体として ”一枚のピクチャー、画像” を認識させているのでデータ量がひどく多い。
そして重要なことですが、”現在、画像認識技術においてはDLがもっとも適している” という事実です。
このことから ”トトデータを画像データとして認識させ、そしてDLで予測させる” というアイデアを思いついたわけです。
これまではトトデータを数値の羅列として ”いかに表現するか?” ということばっかり考えていました。ところがじつはすでに画像として目の前にあったんですねー。
以下に例を挙げてみますね。
ディープラーニングに使う ”トトくじ画像の例”
いずれも対戦カードの最新状態を表現する画像だと思うのですが・・
まずは J2 3/29(日)13:00 栃木 徳島 について
対戦前情報としては http://soccer.yahoo.co.jp/jleague/game/preview/2015032902
から引っ張ってきています。

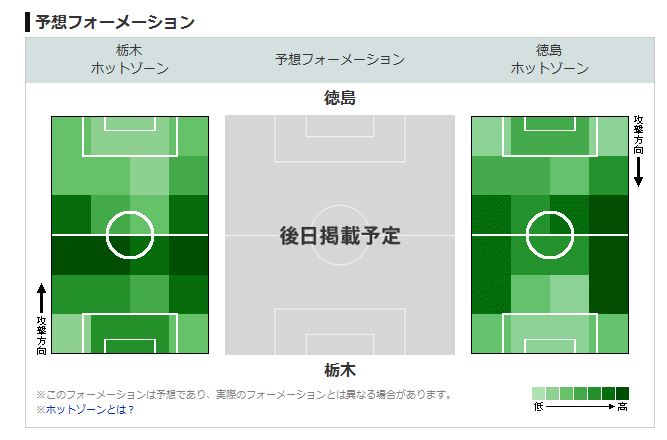
この記事を書いている段階ではフォーメーションについてはまだ掲載がありませんが・・これらの対戦カード画像データを使えば ”面倒な数値入力をせずに、膨大な量の対戦カードデータを画像としてディープラーニングに与えることができる”
しかも最新のデータですね。これはあくまでシュミレーションとなりますけれども(おそらくこういうフォーメーションの対決になるだろうという想定)現在、僕が行っているデータ構成作業よりも早く確実にデータを作成できます。
もうひとつの例は http://www.football-lab.jp/ というサイト。何度も紹介してますが、Jリーグに関するデータサイトとしては非常に優れています。独自の指標や画像も豊富ですね。
このフットボールラボの注目コンテンツとしては ”preview” というページ。
ここは対戦カードについて事前の情報が豊富にあります。ここから画像を引っ張って来てもいいかなと思います。
あと、拡大解釈として、以下のようなよくある対戦チーム比較表なども有効かもしれません。普段は表の中のテキスト情報のみをコピーしてデータとして利用しているわけですが、これを画像データとして利用してみる。まあ妄想なので実際に実現可能かどうかは未知数ではありますが。

画像として保存してある ”テキストの違い” を上手く認識してくれるとは思うのですが、あんまり自信はありません。もしも上手くいかない場合は・・予想フォーメーションなどの、”より絵的な” 画像データっていうのを片っ端から試してみるしかないかなと思います。
この画像認識が上手く機能すればデータ処理は劇的に改善するはずだ
さて、まるで夢物語を書いているわけですけれども・・実際にこれら述べてきたことが実現すれば、これまでの予想手法が劇的に変わって、あるいは劇的に改善するかもしれません。
従来はたくさんのデータを目で見て、そして脳内シュミレーションをして、仮説をたて検証し、そして予測をしていました。これからはパソコンに画像を認識させて、そして過去結果と照らし ”求めている解はコレ” っていうのを計算して返してくれる。・・かもしれません。
画像認識技術によるトトくじ予想で想定される具体的な問題点について
さて、現在、夢見ている ”将来的トトくじ予想プロジェクト” についての概略は以上となります。今度はこのプロジェクトに関する ”想定される問題点” について書いてみましょう。
事前データと事後データについて
まず最初に・・過去何度も書いてきているわけですが・・
トトくじ予想における説明変数は、確定要素しか使えない(ただしシュミレーションは除く)
いつ、どこで、誰とだれが戦うか?
予想している段階で確定していることはこれだけです。したがって予想=シュミレーションなんですね。
データってのは過去事例の集積であるので、これをずらっと並べても予想用データとはなりません。なぜなら予想しようとしている対象回のデータが上で述べた ”組み合わせ” しか分からないからです。説明変数として成り立つようにデータ構成を工夫しなければならないんですね。
以下に例を挙げてみましょう。
まずは予想用データとして成立するケースです。データ構成としては良い見本ではありませんので、そのあたりはご了承ください。
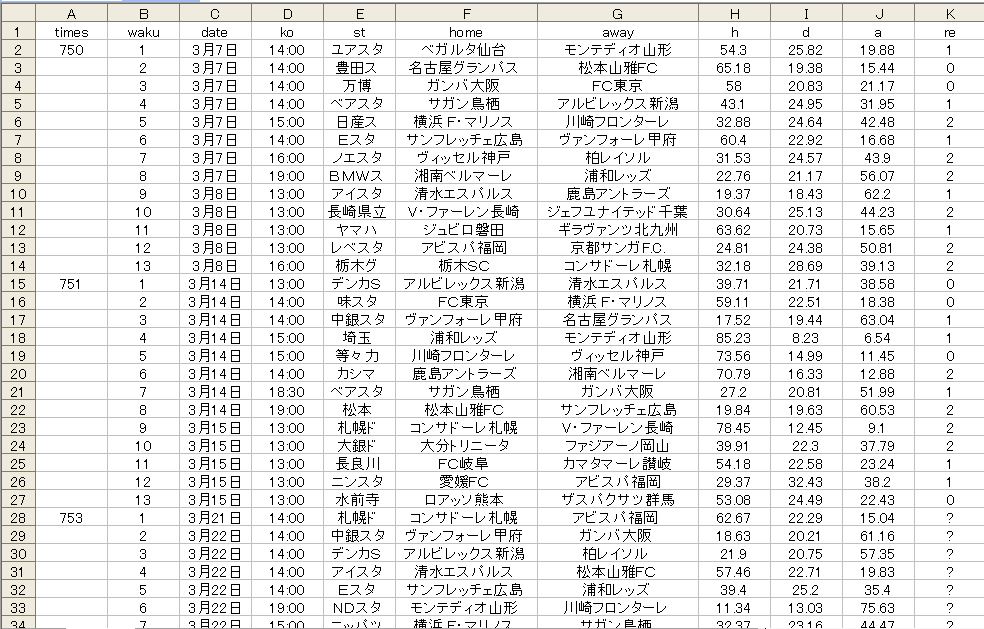
僕が機械学習によるトトくじ予想に興味を持った初期の頃のデータ構成です。
重要な属性としては、試合会場、対戦カード、そして支持率ですね。列の右端に目的変数を持ってきています。このデータの場合、事前に分かってる(知っている)情報しかありません。シュミレーション的要素は皆無であり、教師データとして今季の事後データが与えられています。750、751 と前回、そして前々回の試合結果と支持率を与えているわけです。
WEKAによるテストでは結果はめちゃくちゃ悪いです。笑っちゃうくらい。。まあ、それは置いといて・・
話は戻りますが、このように試合前に確定している要素ってのは ”過去の戦いぶり” しかありません。これをいかにしてデータ化するか?
事前に知りえる情報を消えてしまう前にすべてデータ化する
要するにデータ化の問題ってのは、ホームとアウエイ それぞれの過去の戦いぶり、および直近のチーム状況ってのを数値化することにあるんですね。それの解決策として ”一枚の画像” というアイデアがある。
これを累積、収集して、双方のチームがぶつかったときに ”どんなことが起きたか?” っていうのを記録していく。
この作業を行うときの問題点は ”画像データが消えてしまう” ってのがあります。つまり試合後にはサイトからなくなってしまうんですね。更新されて公開されなくなってしまう。だから事後の検証ができない・・
解決策としてはウェブサービスを使ってデータを呼び出す?
んで、少し考えたんですが、”データベース” にアクセスすれば呼び出せるかもしれない・・ということです。これはデータ公開元が応じてくれればの話なんですが。
たとえばヤフー。ここはAPIでたしかできるんじゃないかと思うんですね。スクリプトを書いて ”getなんとか” で、できるんじゃないかと。
あんまり知識がないんで確かなことは分からないんですが、過去記事についてヤフースポーツの ”みどころ” ってページを過去に遡ってデータを獲れないかなあと。まあ、今からでも遅くは無いので、少し事前データとしてお試し収集&分析でも始めようと思っています。
画像データの扱いについても情報を集めて理解しなきゃいかんとですね。。
以上、僕の妄想でした。
うまくいけばいいなあ。

コメント