
第936回 トト予想 メインはJ2
今回のトトはJ2がメイン。初回予想は以下のようになりました。
J2 18節 予想
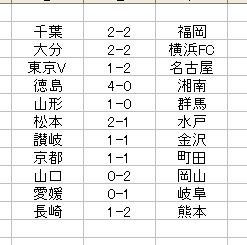
キャリーオーバーもないし、少額で様子見がいいか? J3 は追記します。
J3 12節 予想
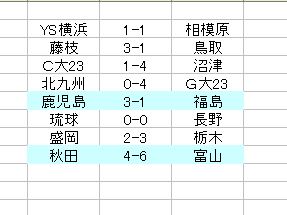
秋田ー富山 のスコア予想がちょっとヘン?
全体の予想を通してなんですが、スコアそのものじゃなくて、勝敗関係だけ見ていただければと思います。スコアで予想していますけれども、なかなかストレートで当てるというのは難しい。スコアはほとんどの試合ではずれると思います。
勝敗についてはある程度はイケるんじゃないかなぁ。
追加予想
毎回やり方を変えて予想するのもいいんですが、比較検討するための基準のようなものがあった方がいいと感じていたので、そういうヤツを載せておきます。
定点観測みたいな感じか。
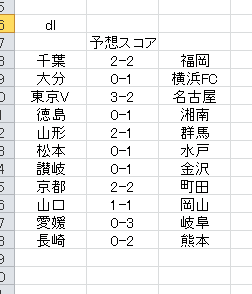
ズレまくるかもしれないですけど、これが基本のやり方における今回の予測結果ということで、今後の比較検討に使おうと思います。
感想とか今後の展望とか
キックオフの時間にそって試合経過をチェックしていました。全体としては○かなと。J3に関しても一部を除き良い予想ができたと感じています。最初の予想はすべてGBMという手法によるものです。J3もGBMです。ただまったくの逆張りとなった枠がいくつかあったことが気にかかります。
毎回、予測方法を変えてやっても開催回の組み合わせによってはかなり正解率に差が出るのは分かり切っています。今後は手法を絞るなかで、どうやって精度を上げるかを考えたい。
上の二種類の予想を比較してみると、自分的には後者の方が好き。先にも書いたけれども、これを基本として次回もチャレンジします。具体的に書くと以下のような感じ。
まずアルゴリズムはディープラーニングで。属性は全部使います。関係ないと思われるようなものもカットせず全部使う。なぜかというと、人間の知見とアルゴリズムはまったく違う働きをする。関係性が見いだせないと考えてカットすべきじゃない。
細かい設定については何も変えない。これをいじりだすと際限がないので。何を基準に比較していけばいいか分からなくなります。
出力結果は与えたデータに100%依存します。なのでデータ更新を前提とするならばベストな設定というのは毎回変わる。そのつどグリッドサーチでモデル構築をする。
さらに細かく、もっと精度を高めて予測する
1、特定のチームのみ でデータをソートする。
いつも成功するとは限らないですが、トレーニングデータを細分化してみるのも一つの方法。検証結果を見てみるとそういう事例がある。アルゴリズムを変えただけでは出てこない出力結果を得ることが出来る。
どんなふうに細分化するか? 考えられるパターンはいくつもあるので、どれが最も良いか いろいろ試してみる。比較するのはなかなか難しいけど。
たとえばホームがA、アウェイをBとする。この対戦結果だけを予測するとします。
ホームがA というデータのみで予測した結果とアウェイがBというデータだけで予測した結果というのはいつも同じとは限らない。また逆にいつも違うというわけでもない。同じだったりする場合もある。
ただ同じデータを使ってのアルゴリズムを変えただけの予測よりも良い結果を得られる可能性は高くなる。結局のところ答えは3個のうちのひとつだけであるので、より確率の高い事象を選択する方法としては 「データを変える」 ほうが良いような気がします。
一番信頼できるアルゴリズムをまず固定して、次にトレーニングデータを変えて予測してみる。
具体的には 讃岐ー金沢 ですね。 アルゴリズムの変更や設定のやり直しでも讃岐の勝ちは見えてきませんでした。しかし上のやり方で再予測してみると 讃岐の勝ち という出力が得られました。偶然だと思われるかもしれませんが、たとえばダブルで押さえようと考えた時には どちらを選ぶか かなり選択を後押ししてくれる出力結果じゃないかと思います。
もしかしたら全部の対象試合について、最初からホームとアウェイを分けて予測するのがベストかもしれません。非常に面倒ですが良いかも。


コメント