
トレーニングデータに 実際のスコア という属性を追加する
J1 セカンドステージ 第4節 は ドローが多発して、案の定キャリーオーバーという結果に終わりました。私の予想も惨敗で、9枠中 1個しか当たっていないという まったく悲惨な状況です。普通ならここであっさりとあきらめてしまうところですが、意外なところに突破口があるかもしれない・・ということで、情報を共有したいと思います。
それはすでにタイトルにも書いてある通り トレーニングデータにこれまでの実際のスコアを属性項目として付加する というものです。
つまり、予測モデルを構築する際に、スコア の示す意味情報を他の要素と共にパターンとして織り込むことを意味します。当然ながら テストデータ には、このスコア情報は織り込むことはできません。なぜならそれは 結果を決定づけるものであり、なおかつ 未知の情報 であるからです。
このやり方に どんな欠点、問題があるか ということについては一旦脇において、まずは出力を見てみます。私自身はこの結果を見てかなり驚きがありました。以下がその一覧表です。
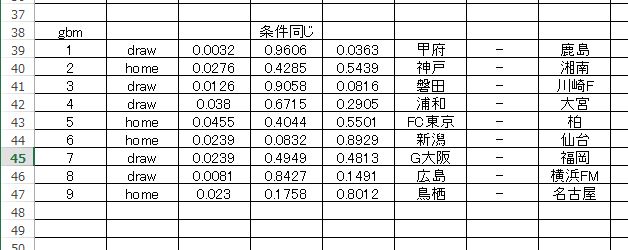
単純にみると、正解枠は6 完全な読み間違いは、FC東京ー柏 と、新潟ー仙台 となります。鳥栖ー名古屋 に関しては誤りではあるけれども、第二候補としてドローが出力されてます。なので評価としては △ かなと。
これまでの予測手法と比較すれば格段の精度向上だと言える。ただし汎化性能に関してはテストしてないので何ともいえないです。つぎに予測条件について備忘録的意味合いで記録しておきます。
使用した予測スキームと属性について
上の予測結果を導いた予測スキームは H2O-3 の GBM です。これまでも何度もこのブログで登場しています。設定は初期設定のままで、どこもいじっていません。
トレーニングデータは 今季の最初からの累積データで、スタッツはフットボールラボのものをマトリクスにしてそのまま使用。これにスコア情報を付加します。ホームチームとアウェイのゴール数をそれぞれ別属性として2枠追加します。属性タイプは NUMERIC です。
最後に全属性項目から以下のものを除外します。除外する理由は、その属性の結果に対する影響力が決定的だからです。除外した属性は以下です。
1、枠内シュート数
2、PKシュート数
3、シュート成功率
4、PK成功率
項目は4個ですが、ホームとアウェイで合計8個の項目をオミットします。
じつは ゴール数=実際のスコア情報 というのも結果そのものであり、予測因子としては決定的なものです。事実 GBM による予測において 属性重要度 としては突出しており、結果に対する影響力の強さ という理由から考えると本来ならトレーニングデータからは除外されるべき性質のものだといえます。
しかしテストデータにおいては空欄のままで走らせる。つまり 「曖昧な状態」で結果を予測させています。
整理すると、実際のスタッツとスコア を用いて構築された予測モデルに「曖昧な状態」というのは一切ない。スコア状況と実際のスタッツは完全に一致しており矛盾しているところはありません。ところがテストデータにおいては「できるだけ結果に対する決定的な因子というのを除外して」あえて曖昧な状態で分類判断をしている・・ということになります。
このことをもう少し詳しく書くと以下のようになります。
テストデータというのは、トレーニングデータ とまったく同じマトリクスであることが条件です。ある目的変数を導くために、その他のたくさんの属性(因子)情報をもとに分類判断を下します。ところが サッカーの勝敗予測 においては 事前に知りえる情報 というのは限られていて、私の行っているやり方においては あくまで疑似的に対戦を行ったと仮定して結果を推定しているだけです。その疑似的対戦のデータに 「結果を決定づけてしまう因子」がなるべく入らないように工夫して、試合結果を推定させるわけです。
結果を決定づけてしまう因子を なぜ除外する必要があるのか?
予測結果を決定づけてしまう因子 というのは、ずばりスコアとか、シュート決定率などです。これらのデータがあると、ほぼその通り の出力しか得られなくなってしまいます。すなわち、疑似対戦をするためのデータを入力した瞬間にその結果が決定されてしまい、その他の因子、属性とのパターンから結果を推定する という機械学習の特徴そのものをぶっ壊してしまうからです。
だからテストデータのために流用したスタッツデータからは、できるだけ試合結果を決定づけてしまう属性を排除するのです。
予測手法については以上です。なにか質問等ありましたらお気軽にコメントいただけるとうれしいです。


コメント