
検証テストするたびに変わる結果・・・いったいこれは何だろう?
以前から感じていたことがひとつ。それはH2Oにおいて、ディープラーニングを用いてトトについて予測する際、同じ条件で走らせても結果が変わることがあるということ。
理由はちょっと分かりませんけれども、やはりこういった事象が起きているのは間違いありません。
機械学習による予測においては、致命的欠陥ともいえる。なぜなら条件設定においての比較が困難になるからです。
例としてひとつ前の記事を取り上げます。
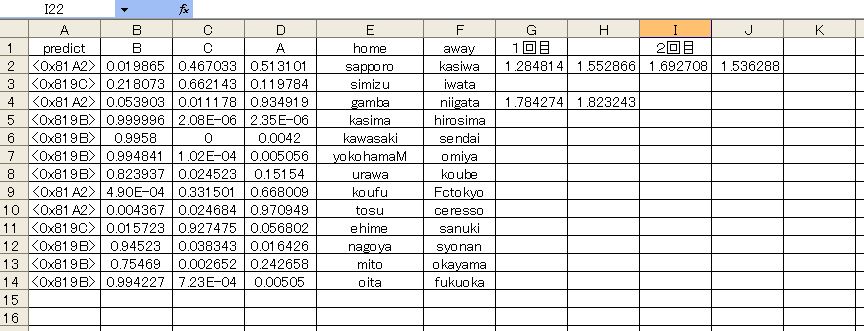
回帰分析における結果
比較してほしい数値は以下のリンクの箇所です。札幌ー柏 のスコアについて予測させた部分。
ここで 札幌ー柏 についてスコアを連続値として予測させているのですが、この時の数値とあらたに検証テストをしたときの数値が変わるのですね。条件としてはまったく同じ設定で計算させているのですが、結果は札幌の方が数値が大きく出力されています。
| 1.692708 | 1.536288 |
まあ大差ない結果ではありますが、これを基に勝敗を予測させるとしたら、まるで正反対の結果になります。いったいなぜなんだろう? と思いますが、こういうものなのかなぁという思いもある。
よく分からんなぁ。
やっぱり乱数なのか? 勝手にやっちゃうみたいな感じですね。
一応、エキスパートの設定で、以下のような箇所がありますね。
Seed for random numbers (affects sampling) – Note: only reproducible when running single threaded.
乱数のためのシード(サンプリングに影響を及ぼす) – 注:シングルスレッドを実行しているときのみ再現可能です。
もしかしてこれなのか?

シングルノードモードにすると何が変わるの?
SEED 乱数の項で触れられている シングルスレッド と、 シングルノードの項・・・言葉がちょっと違います。サンプリングに影響を与える乱数は、この SEED値 をもとに作られているはずなのですが、シングルスレッドを実行しているときのみ再現可能とはどういうことなのか? 何を再現可能としてくれるのか?
試しにシングルノードモードをチェックして同じ条件で走らせてみます。
結果としてはまた違った出力がなされて、やるたびに予測値がやっぱり変わる。まったく同じ数値は示されないが、かといって、トンチンカンな結果でもない。私感だけど、予測精度が少し良くなったような気がします。
結果的にシングルノードモードにしても、同じ予測結果を再現してくれるわけではなくて、「何を再現可能としてくれるのか?」 についてはよく分からない。マニュアルも見てみたけど説明がイマイチ。
僕が困惑しているのは、予測出力が安定しないこと。まあ、シングルノードモードにすれば、多少良くなるという経験値は得られたけれども、これ、どうなんだろう?
同じ条件なのに値が変わるというのは、やっぱり 「サンプリングが一定じゃないから」 としか考えられません。

コメント