
勝つか負けるか引き分けか? 3通りの分類予測
最近はほとんど使っていませんでしたが、久しぶりに3通りの分類による予測をやります。
これまでとの違いは、予測モデルをホーム側とアウェイ側で分けて2本立てとしたこと。下の画像のブルーがホーム側から見立てた予測となり、右側の黄色はアウェイ側データによる予測となっています。
ホームが勝つか負けるか、引き分けるか? 同様にアウェイチームが勝つか負けるか、引き分けるか?
枠によって分類確率はまちまちであり、必ずしも勝ち負けが一致しているわけではないです。これを元に予想を組み立てます。

単純にホーム、アウェイにおける分類確率の一番大きなものを選ぶと下記のようになります。
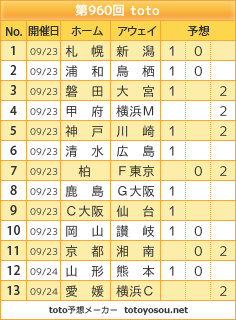
予想母体としては全部当てたいんだけど、「これでもどこか漏れるんだろうなぁ。。」 と思いますね。
数値比較でわりかし大きなところが来てくれるならまだ予測可能ではあるけれども、これがとんでもなく小さなところが来ることもあります。もうこうなると予測不能となります。
お手上げっていうヤツですね。さてどうしようか。
当たらない予想。。やっぱり何か間違ってる。
何シーズンも機械学習による予測を行ってきました。が、しかし満足いく結果というのは得られていません。もうほんとにこれでもかっていうぐらいやってきたんだけど。
どこかに致命的な間違いがある。
与えられたデータを適切に学習すればそれなりの精度で予測できる。これは間違いないです。ではなぜ上手くいかないか?
それは 説明変数がクソすぎるからだ。
もう笑っちゃうしかないけれど、事実その通り。過去データの集積なんてのは説明変数にはなり得ない。あくまでも統計です。
未知の結果に決定的な働きを及ぼす要因、属性が分からないと。やれることはひとつ、その属性を作るか見つけるかしてデータに付加する。
まあこれをやったとしても、完璧に上手くいくとは限りませんが。
追記 検証結果から考えたこと
さて、今回 960回のトトは非常に難しく、キャリーオーバーという結果からも統計的見通しによる予測ではまったく歯が立たなかったわけです。
今回の私の予測はすべてディープラーニングアルゴリズムで行っており、予測の結果を見ると、ほぼ統計的見方から帰結するような結果を吐き出しているように見えます。
つまり、ディープラーニングではあるけれども、結果を見ればそれは 統計的結論 であり、他の多くの方が考えた予想のように見えるということ。
これが 良いか悪いか? という問いには簡単には答えは出せないけれども、少なくとも今現在、僕が使っている予測用データというのは、ディープラーニングでは正確な未来を予測できていない。
これは見方を変えると、データとアルゴリズムが上手くマッチしていないと見ることもできる。もっとも先に書いたように、説明変数がクソすぎる ということもあるかもしれないが、現状で手に入る事前情報というのは限られているので、ないモノねだりをしても先には進めない。
本当はもっと上手くマッチして、よりよく予測できるアルゴリズムがあるんじゃないか?つまり、それぞれのデータには、もっとも予測性能を発揮できるアルゴリズムがあるのではないか?
現実的に考えれば、データの方をあれこれ考えるのはもう手が尽きています。というか、新しい属性を付加することとかは考えたくない。
今あるデータでできることを考えたい。
追記 その2 多重共線性
機械学習の知識としては前々から知ってはいた 多重共線性 という言葉。
重回帰分析における問題として情報はたくさんありますね。というわけで、僕も自分のデータについては気にはかけていた。だけど対策みたいなのはまったくしていなくて、データを作ってそのまんま与えて計算して・・・というようなことをやっていたわけです。
詳しくは興味があれば調べていただきたいのですが、つまりは説明変数同士の相関があまりに強いと上手く予測できませんよと。
たぶん同じようなデータが被っているような状態も多重共線状態だろうということなのだろうと思います。なので、できるだけお互いに相関のないような情報で目的変数を説明しないといけない。
僕がやったのは、ただ単に被っている情報を削除しただけだけど、これだけでも結果がまったく変わってきます。ディープラーニングは やっぱりバカじゃないです。
諦めるのはまだ早い。可能性はあるね。


コメント