
第866回トトくじ 予想 最大予想母体はこうなる。
さて、J1リーグもこれで終わり。予想の最後は 「最大予想母体ですべての正解を含める」 という課題をクリアして終わらせたいと思います。
今回載せる予想は現実的組み合わせではありませんが、まずはすべての正解を含む予想案ができないと話になりません。確実に13個の正解を残したまま、現実的買い目になるまで削減することが至上命題なのですが、まずはある程度絞り込んだ状態で 「13個の正解を残す」 ことを目標として予測した結果が以下の表です。
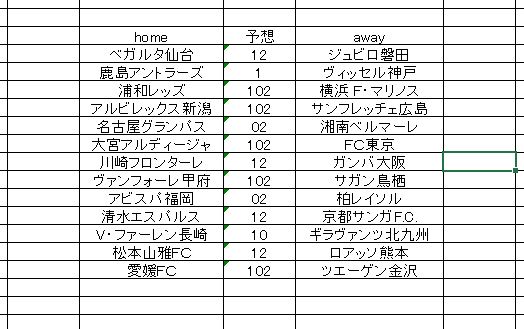
算出方法はいつもの機械予測。各枠ひとつに付き、計8回の予測を行って、そのすべての出力をまとめてみました。アルゴリズムは4種類、トレーニングデータはホーム側とアウェイ側それぞれで作成。4×2 で計8回 という内容。
2枠 鹿島ー神戸 はシングルです。神戸もマークしたほうが良さそうですが・・さて? 9枠 福岡ー柏 などは 柏シングル でもよさそうです。。いろいろ考えどころはあるのですが、現実的にはこの状態からもっと 「どこかを削らなければならない」 難しいです。
第886回トト予想 絞り込み予想案
4種アルゴリズムによる表と裏の8個の予想案から、ふたつの案を選び、合成した予想です。各枠の予想アルゴリズムは統一してあります。本来なら枠ごとに 「最適なアルゴリズム」 を検証したうえで決めるのがベストですが、それをやると作業量がハンパないことになります。やり遂げる自信はないのでこれで行きます。工夫次第では簡単に検証できる可能性もあるので、いずれ挑戦してみたい。
今回の案、これでもまだ大きいですが、これ以上の削減は無理っぽい。
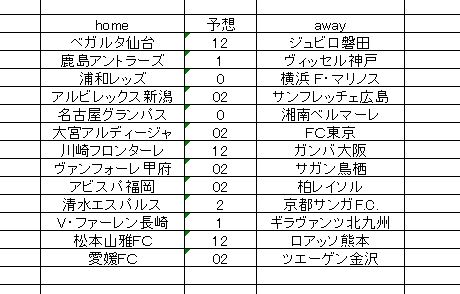
浦和 を外してあります。大宮もなし。清水も神戸も名古屋もありません。逆にマークなどせんでもいい箇所にあえてマークしているような感じを受けます。。でも仕方ない、勘では買わないと決めているので。実際の買い方は、2等あるいは3等保証削減バラ買いです。すべての正解がこの予想案に含まれていれば、必ず2等、もしくは3等が含まれるという買い方。
さてどうなるか? 楽しみです。結果を待ちましょう。
ディープラーニングによる試案
さて、ストーカーのようにしつこく気にしているディープラーニング。今後の参考としてひとつだけ予想結果を載せておきます。購入は間に合いませんでしたが、先に挙げた予想とはそれほど大きく変わることはなかったです。
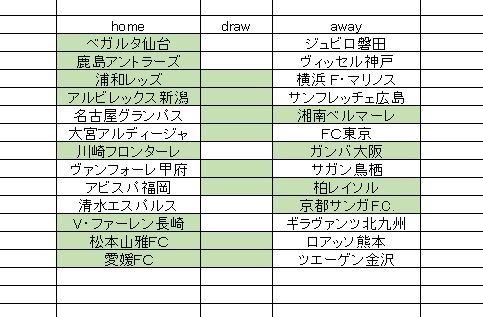 色付きが予想です。全体でダブル7という比較的大きな予想母体。清水など、ほぼ確定 というような枠をハズしてマークしていたり、シングルドローとかもあって、何とも不安な予想案となっています。これをそのまま買えといっても、まず誰も買わない。私も自信が持てない。使っているデータもこれまで試したことがないものであり、まったくのテストという位置づけです。
色付きが予想です。全体でダブル7という比較的大きな予想母体。清水など、ほぼ確定 というような枠をハズしてマークしていたり、シングルドローとかもあって、何とも不安な予想案となっています。これをそのまま買えといっても、まず誰も買わない。私も自信が持てない。使っているデータもこれまで試したことがないものであり、まったくのテストという位置づけです。
ネタですね。ネタ。
結果を見てみる
まだ終わってないんですが・・・
負けです。打つ手がありません。あれだけ大きな予想母体でもとりこぼしています。
参りました。鹿島ー神戸 が ハズレ。。これは出力結果がすべて鹿島だったからです。仕方がない。。今回の手法は通用しないことが証明されました。
とにかくすべての正解を含んだ予想案ができないことには前に進めない。
トリプル5、ダブル7、シングル1 これが今回のマルチスタイル。予想案を合成すると結果的にこうなっただけで、自分から選んだマルチではないわけですが、こんなに大きな母体でもハズレが出現するとは夢にも思いませんでした。。
まあ、神戸がノーマークだったのは正直不安ではありましたが、「まさか・・」 という感じですね。次は J2 。挑戦は続きます。
追記 すべらない予測方法を求めて検証中
なんとも腹立たしく、情けない結果となった今節。途中で放り出すことはしたくない。なのでしつこくやる。やると言ったらやる夫ですね。
単純なことなのですが、データをちょっといじるだけで光が見えてきました。といっても第一段階の最大予想母体を導くまでのことですが。 鹿島ー神戸 で導けなかった 神戸の勝利ですが単純な操作で導くことに成功しました。ストレートに神戸勝利の予想というわけではありませんでしたが、第二候補として挙げることには難なく成功。その他の枠についても現在調査中です。
「3通りの結果から可能性の高いものをふたつを選ぶ」 これが第一段階。トト予想の経験者なら、思ったより難しいことは承知しているはずです。まずはここを確実にモノにしたい。そのために考えた方法が次になります。
一般的な人力予想においては支持率やらリーグ順位がその目安になりますが、機械学習の場合は統計から導かれる確率が目安になります。「一番安定した汎化性能の高いアルゴリズムは何か?」 という観点から考えると答えは次になります。
私が 「有効な分類アルゴリズム」 として挙げるのは以下のふたつ。
1、ナイーブベイズ
2、ランダムフォレスト
いずれも超有名で、いわゆる 機械学習におけるベンチマーク的アルゴリズムだと思っています。これらのアルゴリズムでまず 3/3 から 2/3 に絞ります。一番確率の高いものから二つ選びます。予測精度はデータの出来に依存している部分が大きく、一概に評価できるわけではないです。そのあたりはデータ構成を何度も試行する必要があります。
じつはこれらの作業である程度確信を得られても、まだ完全ではありません。トト予想のケースではアルゴリズムに与えるデータ、つまりトレーニングデータには 「ベストな形」 というものがありません。ひとつのフォームにこだわると絶対に正しく分類予測できない壁にぶち当たります。重要なことですが、問題はアルゴリズムの選択ではなく、トレーニングデータの質にあるのは間違いないです。
現状で出来る最善のことは、「有効性、正確性が確認されたいくつかのフォーム、データ構成を用意して、それらで予測した結果を比較検討すること」 です。
こうやって最善を尽くしたつもりでも、1枠か2枠ぐらいはダブルでもハズレる可能性は残る。いや実際にそういうことはこれまでもたくさん事例があります。もはや運しかないのでは? などとつい考えてしまうことはしばしばです。資金に余裕があれば、第二、第三の予想案で予測強度みたいなのを高めるしか方法がないかも知れません。


コメント