
第874回トトくじ予想母体
今期累積データを使って H2O-3 にある4種類のアルゴリズムすべてを使った予想を挙げておきます。チューニングやらトレーニングデータの作り方などで同じアルゴリズムでも全く違った結果が出力されるのですが、経験的にもっとも良いと思われるやり方で走らせてみました。出力結果はすべての合成となっています。鳥栖ー広島 だけトリプルとなっていますが、これは出力が完全に割れてしまったからです。
アルゴリズムの名称は以下です。
1、ディープラーニング 活性化関数は MAXOUT
2、GBM
3、ランダムフォレスト
4、ナイーブベイズ
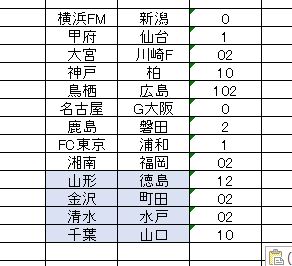
マルチが多すぎてこのまま買うのは現実的じゃないです。それに J2 すべてがダブル買いというのも日程的にどうかなという感じもします。マルチを多用するなら初日のJ1に重点的に配置したほうが楽しめるのは間違いないですしね。初日が穴だらけで二日目にもれなく正解してもまったく意味ないですから。
とりあえず累積データを使用したベストな予想がコレだという感じです。おそらくJ1では取りこぼしがあるだろうと思います。J2 もまったく自信はありません。半分ぐらいはハズレかもしれないです。
前回ぐらいからチーム別データによる予測も行っています。そこそこ良い感触はあるのですが、データの作り方もいろいろ考えられるわけで、まだベストな構成が分からないといった状況です。たとえば前節 j1-2-11 広島ー大宮 などはどうやっても 大宮の勝ち という出力結果は得られませんでした。これは個別データによる予測の話で、累積データを使ってまとめて予測してしまう方法とはまたべつの話。もっと簡単に全問クリアできるかと思っていましたがやっぱり難しいです。
今節もたくさんのチーム別データを作って予測しています。今節の結果が出たらさっそく検証してみようと思っています。
とりあえず感想を・・
累積データを使った予想はのっけから二つはずし。だめですね、使えない。今のところ当たっている予想はチーム別データによる予想のみ。上手くいってくれればいいのだけれど。
大宮ー川崎 大久保が退場?! 残り10人 やばくないですか? 川崎 荒れてるー、ああ、大宮勝っちゃいました。
さて、J1 終了しました。予想の方はぜんぜんダメ。累積データを使って全枠を一括で予想する方法はムラがありすぎてダメです。良いときはいいんですけど今節のようにまったく合わない時もある。
今後の予想について
現在、トレーニングデータの構成、そしてテストデータについても大幅にやり方を変えてテスト中。基本的に一括での予測は使わないことにし、チーム別、そしてホームアウェイの違いも考慮してデータを作ります。
トレーニングデータに使うデータ量についてはまだいくつか考えなければならない部分はあります。しかし属性の示す数値の集合特徴が全チームに共通しているとする考え方は見直すべきかもしれません。その意味からトレーニングデータおよびテストデータはチーム固有のものにします。
詳細は省きますが、前節 どうしても予測できなかった 広島ー大宮 について、上記のやり方で検証した結果が以下になります。
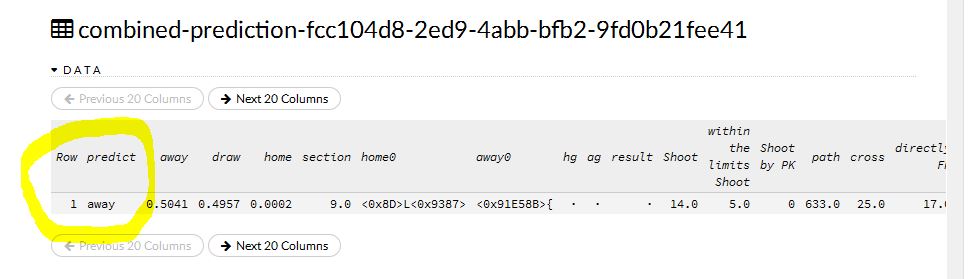 画像が少し小さいですが、上はディープラーニング MAXOUT による予測結果。確率をみるとドローも高いですね。画像の上段にはテストデータの属性項目が示されています。漢字表記でチーム名を入力してありますので、実際に走らせると上のように文字化けしてチーム名が表示されます。
画像が少し小さいですが、上はディープラーニング MAXOUT による予測結果。確率をみるとドローも高いですね。画像の上段にはテストデータの属性項目が示されています。漢字表記でチーム名を入力してありますので、実際に走らせると上のように文字化けしてチーム名が表示されます。
下は同じテストをナイーブベイズで走らせた結果です。
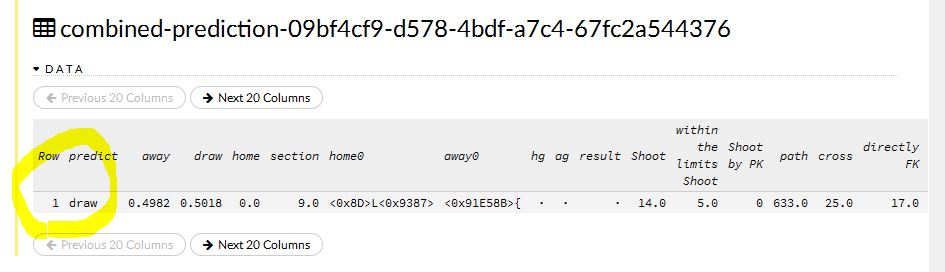
こちらは ドロー が一番確率が高く予測されていますが、数値を見るとやはり アウェイ も高く、僅差となっているのが確認できます。
最新の j1 12節 の検証についてはページを改めてやりたいと思いますが、このように前節 広島ー大宮 についてだけ見てみると、従来の予測手法より予測精度が高まっているのではないかと感じさせてくれます。トレーニングデータやらテストデータの作り方にもいろいろ問題はありますし、検証を重ねないとはっきりとしたことはまだ言える状況にはありませんが、予測手法としてはかなり前進した感触があります。


コメント