
第873回トトくじ 13枠の予想
今節の予想は以下の通り。
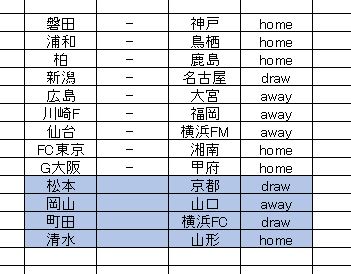
ディープラーニングによる予測です。実際には他のアルゴリズムも使ってものすごくたくさんパターンを出しましたが、結局考え過ぎてしまって絞り切ることができず。
過去の検証結果から方向性を決めようと思っても予測結果の正解率には相当ブレがあるので、どこに基準を置いて考えればベストなのか分からなくなりました。今節のやり方はとてもシンプルで、今季の累積リーグ結果というものにはまったく重きを置いていません。直前のリーグ戦結果を重視しているモデルです。
おそらくパーフェクトは無理だと思います。キャリーオーバーもあることだしマルチを使って攻めたい気持ちはあるのですが、やっぱり当てずっぽうはイヤ。なにか自分なりの根拠をもってマークしたいんですね。現状で考えられるマルチマーク用の手法も結構ムラがあるようで、イマイチ自信が持てません。
試しに作成した ドロー推定のための表 を挙げておきます。
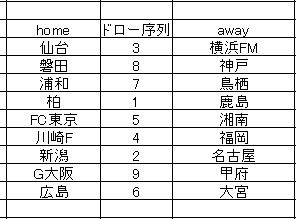
ドロー序列 と書かれた数字は 1から順に 「選択の順序」 になっています。一応各チームのゴール数の回帰予測から導いた数字なんですが、このやり方も検証結果においては相当ブレがありまして、本格的に運用するには問題があることが分かっています。
今考えてることは、やっぱり基準となる予測モデル構築法をきちんと見定めることと、そのモデルを基準とした場合に、もっとも効果的なマルチマークの手法を考えることです。とにかく現実的範囲に収めるのが絶対条件。気長に続けます。
結果検証 ディープラーニングは有効だ。ただし使い方には工夫が必要
さて、J1 11節 終わりました。とある予想サイトを一通りチェックしましたが、大宮の広島に対する勝利という予想がなかなか想像しにくかったようで、ほぼノーマーク状態だったようです。あとは名古屋勝利ですか。闘莉王復帰の効果なのか分かりませんけど、名古屋踏ん張りましたね。データからはとても買える気にはなれない状態でしたが「ひょっとして」という予感はみなさんあったんじゃないでしょうか。
さて肝心なディープラーニングによる予想、今節はわりかしツボにはまったようで、最初に掲示した予想表においては 6/9 の正解率です。まあ 「こんな程度」 といった感じなんですけど外すときはもっとひどいですからね。まだマシな方だと思います。
外し方が一番ひどいのは 川崎ー福岡 これはいただけませんね。過去履歴から 「もしかして?」 という感じはありましたが、そんなに甘くはありません。大宮勝利の出力に関しては 「えっ?」 という感じでしたけどディープラーニングはちゃんと仕事してくれたようです。あと 新潟ー名古屋 これはドローという予想でした。結果的にはハズレですが、スタッツをみると新潟の CK の数が多くて、かなり攻め込んだことが伺えます。流れとして良い読みだったと感じますね。名古屋がよく踏ん張ったということでしょう。
磐田ー神戸 については磐田勝利の予想でした。ここは吐き出された確率的にもまったくの見当違いでした。
以上総合すると、まったくの見当違いは 2枠・・磐田ー神戸、それから 川崎ー福岡 でした。使った予測スキームは H2O-3 ディープラーニング です。活性化関数はグリッドサーチでもっとも良い数値を出したものを選択。トレーニングデータでオミットした属性は ナシ。すべての属性を オン にして走らせています。
このディープラーニング、じつは妙なクセがありまして、今季リーグ戦の累積データをトレーニングデータとして使うと 「まったく使えない代物になる」 という感触があります。これはデータの性質によるものなのかもしれません。はっきりしたことは分からないのですが、累積データを使うならランダムフォレストとか、GBM、あるいは ナイーブベイズ などを使った方がよりしっくりくる結果をを得られるケースが多いです。
私流の経験則から言えば、ディープラーニングによるサッカー予測においては 超短期データをトレーニングデータ、教師データとして使う方が良い結果を得られる可能性が高い。
これは静的データと動的データによる違いからくるものかもしれません。サッカーの試合は動的事象であり、写真の分類とはまったく性質が違いますから。「過去はそうでも現在は違う」 というのを上手く捉える必要がある。累積データによる大まかな傾向を踏まえつつ、「今」の傾向も取り入れて予測する。これを機械にやらせるにはどうすればいいか?
詳細については控えますが、現状で有効だと感じる予測手法は以下。
1、超短期のディープラーニングによる予測
2、累積データをもとにチーム個別でソートしたデータをディープラーニングで走らせる。
3、以上二つの方法で予測させた結果をマルチで買う。
これはJ1限定であり、J2で同じ方法を使っても上手くいくとは限りません。J2はちょっと違う感じがしていて、アプローチそのものを根本的に変えないと上手くいかない可能性が高いです。


コメント