
第856回トトくじ予想 引き続き H2O-3 gradient boosted methods を使って予測する
私の中では比較的良い印象のある gradient boosted methods
今節もこれを使ってトトの予想に臨みます。予測手法の種明かしは もうすでに過去記事で書いていますが、もう一度整理しておきます。
目的変数はずばり結果そのものを使っています。いわゆる3WAYであり、HOME,DRAW,AWAY のどれかに分類予測をさせる。
説明変数、いわゆる 属性(attribute)には、フットボールラボにて公開されている スタッツ を利用しています。タイミングよく はてな にて他の方が 機械学習によるサッカー勝敗予想をされている記事がありましたので参考にされるとよいでしょう。
R Decision Tree 決定木でサッカーの勝敗を予測する – DSL_statblog

0. 使用するデータと仮説立案今回はサッカーの勝敗・試合内容の履歴データから、勝敗の要因や勝敗を予測するモデルを作成してみたい。使用するデータはこちら(出典:F…
予想のやり方は違いますが、基本的な考え方は同じです。ちなみに上のリンクで紹介されているアルゴリズム Decision tree ですが、WEKA でも同じように試すことができます。私が現在使っている最新版には AUTO WEKA という予測スキームがあり、それを使って分類させると、私の作成したデータにおいては Decision tree が選択されます。おそらく自動で 一番良いと考えられる予測スキームを割り出してくれる機能なんだと思いますが、偶然にも紹介した記事とアルゴリズムが一致していて、奇妙な感じを持って読まさせていただきました。
※ ちょっと記憶が間違っていました。選択されるアルゴリズムは Decision stump でした。
記事によると、「絶望的に悪い予測精度」 と書かれていますが、8枠中 5コも正解していれば 「悪くはない」 と感じます。
予想手法の決定的違いは次の点です。
紹介記事は 事前に知り得る情報のみ使って予測させるという方向性。私のケースでは 疑似対戦させたものを分類予測させている。
これは当然のことなのですが、サッカー予想において事前に十分な時間をもって検討できる要素には、 対戦相手、場所、開始時間、過去履歴しか分かりません。もう少し詳しく言えばいろいろありますけれども、それほど情報は多くはないです。しかも数値化できる情報となると限られてくるし、そもそもどうやって数値化していいのか分からない属性もあります。
サッカー予想には どんなデータ、情報が必要なのか? そしてそれはどう数値化できるのか? についてはずいぶん悩んできましたが、現在は 直近のスタッツデータ を流用する という方法で予測させています。
トト予想の肝 スタッツデータの流用に関するアイデア
流用したスタッツを用いて、対戦シミュレーションを行い、その結果を機械判別 分類予測する。
これが私の行っている予測手法です。
仮に、完璧に これから対戦するチーム同士がどういったパフォーマンスを示すのか? といった具体的数値が分かれば予測精度が飛躍的に向上することは間違いないです。
問題は、 どのスタッツを流用すればいいのか? ここに尽きます。未知の対戦において、これから示すパフォーマンスにできるだけ近いものを選びたい。しかしその方法が分からない。
ごく簡単にシンプルにざっくり考えると次のようになります。
次に対戦するチームは、これまで戦ってきたチームの どれに一番似ているのか?
この 類似性 をどうやって判別させるか?
機械学習においては クラスタリング というものがあることは知っています。いわゆる 教師ナシデータ(つまり予測しようとしている事象の答えが示されていない状況)で、データ群(インスタンス)を似ている者同士に分けることだと理解しているのですが、たとえばこのクラスタリングというテクニックを使って、次の対戦相手が示すパフォーマンスを推し量ることができないだろうか?
あまり知識がないので、具体的なことはまだ書けないのですが、距離関数 というもので類似性を判別させる。あるいは トポロジカル データ アナリシス というもので パターンの類似性について分析する。
仮に、こういった手法で 実際のスタッツと非常によく似たテストデータを与えることができ、なおかつ、その分類予測精度が現状の80%程度を超え、95%ぐらいまでにアップさせることができれば、比較的小規模のマルチ買いを使うことで、限りなく1等賞金を獲得できる可能性が高まります。
とりあえずは直近のデータでひとまず予測を出し、そのあとで 過去データから選択されたスタッツ による予測を出したいと思います。
前節スタッツのテストデータによる予測 J1編
以下が J1 第2ステージ 1節 の予想となります。

枠ごとの確率、リーグ順位も合わせて比較してみてください。鹿島ーガンバ大阪 などは 鹿島勝利 と予想されていますが、ドロー確率も高くなっていることが分かります。宇佐美選手が移籍でいなくなっていますが、そう簡単に鹿島勝利と見ていいのか 迷うところですね。
私の作成したデータには個別選手の情報はいっさい入っていません。いわゆる サッカーにおけるファンダメンタル要素 (移籍、ケガ、欠場など)に注目される方は注意してください。
のちほど追記します。
前節スタッツを流用したテストデータによる予測 J2編
アルゴリズムに H2O-3 gradient boosted methods を使用した J2-21節 の予測は以下となります。
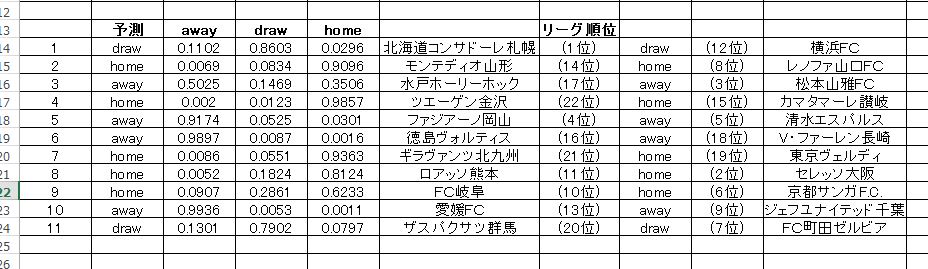
表の見方は先に挙げた J1 とまったく同じです。単純にリーグ順位と比較してみると、かなりおかしな予想に見えますね。
ここからさらに J1,J2 ともに テストデータのみ、あるいはケースによってはトレーニングデータも内容を変えて、もうひとつ予測を出してみたいと思います。
過去のリーグ戦直接対決スタッツを使用した予想
第856回トトくじ 13枠の並び順で予測表を整理しました。表の見方ですが、左側に合成の確率、真ん中付近に ダブルで買うなら・・というように序列を付けて記入してあります。ピンクでマーキングしてある行は、過去の直接対決データがない枠ですので、前節データによる予想をそのまま使っています。。
直近の前節スタッツを使った予想と、過去の直接対決データを使った予想、最初は別々に分けて表示しようと思ったんですが、かえって分かりにくくなるかもしれないと考えて、このように合成した確率でを序列を付けました。
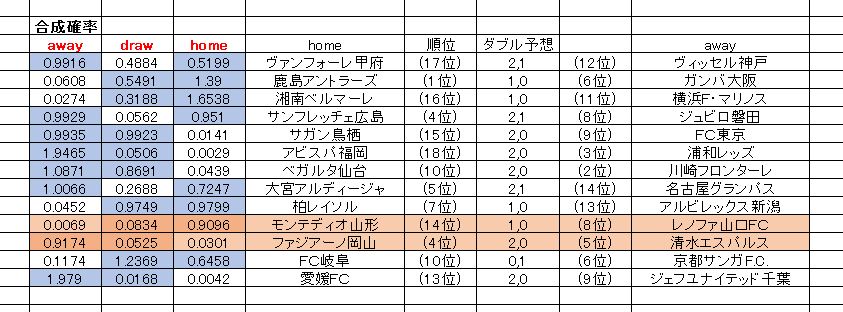
枠、組み合わせによっては、非常に低い確率のものも第二候補としてダブル予想に入れてあります。削減を考える場合には真っ先に消したくなると思いますが、可能性としては一応 アリ なので注意してください。
まずはダブルでの完全予想母体を目指していますが、残念ながら現状では 取りこぼし の可能性はあります。過度な購入には気を付けてください。キャリーオーバー時にマルチ買いを多用するのがよろしいかと思います。
第856回 トトくじ予想 番外編
夏場はナイター試合ということもあり、開始まで時間的余裕がありますので 番外編 ということでディープラーニングを使った予想を挙げておきます。
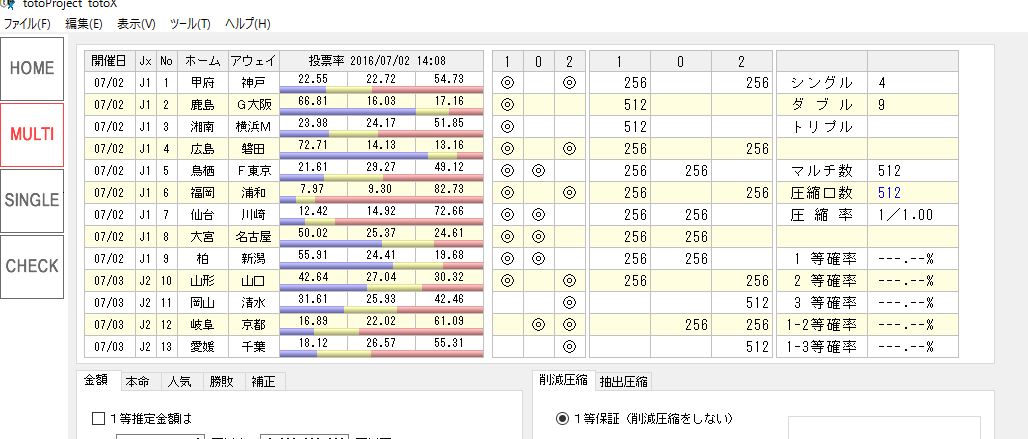
トレーニングデータ には、前節のスタッツのみを使っています。つまり J1 においては全部で9行しかない非常に小さなデータとなります。J2では11のインスタンスとなります。
テストデータは GBM で使ったものと同じで、直前のリーグ戦スタッツ、つまり前節のスタッツを、これから戦う組み合わせで差し替えたものを使います。
なぜ このような方法をとるのか? 理論的に説明することはできません。 ディープラーニングに関しては、なぜか今季のリーグ戦スタッツの累積データをつかってモデル構築したものよりも正解率が良いケースがあります。
データが多くなればなるほど傾向などが顕著になってきて、一見すると より良い予測ができそうに思えますが、それは静的なモノを対象とした場合であり、トト予想 とはちょっと性質が違います。統計的な考え、見方からすると、どうしても 頻度主義的 な考えに捕らわれてしまって、「あれれ?」 みたいな意外な結果を予想することは本当に難しくなってきます。
これらの意味から、トレーニングデータを直近のものに絞って予測させるわけです。やり方や考え方は間違っているのかもしれませんが、未知のものを上手く予測することが目的ですからね。自分流でやります。
上で挙げたマルチ予測は、ふたつの活性化関数を使って予測させたものです。今回 選択した関数は以下の通り。
MAXOUT、RECTIFIER のふたつ。ドロップアウトは使っていません。H2O では全部で6種類の活性化関数が選択できます。10-FOLDS クロスバリデーション ですべての関数について初期設定でテストを行ってみましたが、正解率に顕著な違いは見られませんでした。若干の違いはありましたが、それほど気に留めるレベルではなかったです。この時のテストデータには 今季累積スタッツデータ を使用しています。
この予想は実験(テスト)という位置付けですので、どれくらい正解を含めることができるのか 楽しみに結果を待ちたいと思います。(あるいは ガックリ するかもしれませんが。)
結果検証
J1 終了しました。気が早いですが さっそく結果を見ます。
まず j1全体ですが、いずれの予想でもパーフェクトはなりませんでした。ダブル予想でも ガンバ、マリノス は完全にハズしています。データからは 湘南はマリノスに勝てていないことは分かっていました。しかし機械予想ではそういったいわゆる 相性 のような情報というのは読み取ってくれません。そういった情報をデータとして つまり属性のひとつ として追加してみるのも対策としては有効かもしれません。
前節スタッツを比較させて予想するスタイルで、上手く予想が当たるケースとそうでないケースの違いは何なのか?
事後検証において、流用したスタッツと実際のスタッツの比較検証をしたことはまだ一度もないのですが、おそらく想定したスタッツとはかなり違っているはず。論理的に考えれば、そうでなければ辻褄があわない。勝ったチームは、そうであるべきスタッツを示しているはずだし、逆に負けたチームは対戦相手よりも当然スタッツ内容が劣っていると考えるのが自然です。
ドローはスタッツだけを見て判定するのはむずかしいというのは、感覚的にも一致します。しかし勝ち負けについてはエラー率も低く、機械判定において 間違えるということはかなり可能性としては低い。明らかに流用したスタッツ自体が実際のパフォーマンスとはかなり違っていると推測できます。
チームの総合評価というのは、対戦相手のレベル、もしくは状況でしか判断できないので、機械的に 前節スタッツを比較分類予測させる手法においては、こういった予測ミスは今後も起こることは間違いないです。何か突破口となる考えはないか。
事後検証 PART2
J2 もすべて終わりましたので、あらためて振り返ってみましょう。
J2もパーフェクトとは程遠い結果となりました。合成確率によるダブル予想も上手く予想できているとは言い難い。先にも述べたように、「流用したスタッツが、あたかも実際のスタッツであるかのように見せかけて、それらを機械判別させる」 という予測手法なので、そもそも実際とは大きく離れたスタッツを流用し、それで分類すれば当然のごとく全部ハズレとなります。
アルゴリズムを変えても基本的には大きく結果が変わることは稀だと思います。実際のスタッツのみで構成されたデータを、交差検定でブラインドテストすると、その結果は おおよそ80%程度の正解率です。仮に流用したスタッツがすべて実際のスタッツとよく似ていたとして、13枠で考えると、およそ 10枠 の正解が期待できる。(すべてシングルでの予想で)
前節スタッツのみでの正解は わずか 5枠のみ。合成確率によるダブル予測でも 8枠 の正解でした。期待値を大きく下回っています。んで、原因は何かというと、やっぱり 流用したスタッツ にあるんじゃないかと思うわけです。アルゴリズム や、もしかして トレーニングデータ にも問題があるのかもしれませんが、その可能性は低いと思う。
手間は相当かかると思われますが、スタッツの研究というか、そういうのをちょっと考えないと進展がないような気がしてきました。とりあえずは 流用したスタッツと実際のスタッツの ズレ というのを確認してみたい。


コメント