
WEKA による J2-17節の予測
ここのところ WEKA ばっかり使っています。H2O-3 によるディープラーニングなどの予測については 現状では進展が望めないと判断していますので中断しています。いろいろ試してみたいことはあるのですが知識が追いつきません。
さて、今回 使用するスキームは以下の通りです。
Scheme: weka.classifiers.meta.AttributeSelectedClassifier -E “weka.attributeSelection.CfsSubsetEval -P 1 -E 1” -S
これは たくさんある属性を ある基準によって ふるいにかけて軽くして分類するものです。いわゆる次元削減をしてから j48 の決定木分類で予測をしています。
次元削減の基準については いろいろ選択ができますし、メインとなる分類器も選択可能です。今回のケースではすべてデフォルトで予測を行いました。
以下が予測結果です。

普通ならまず買わないような目もありますが、結果を待って判断したいと思います。
ちなみに今節の予測に用いたデータの10クロスバリデーションの結果は以下のようになっています。交差検定に用いた分類スキームは上の予測とまったく同じです。
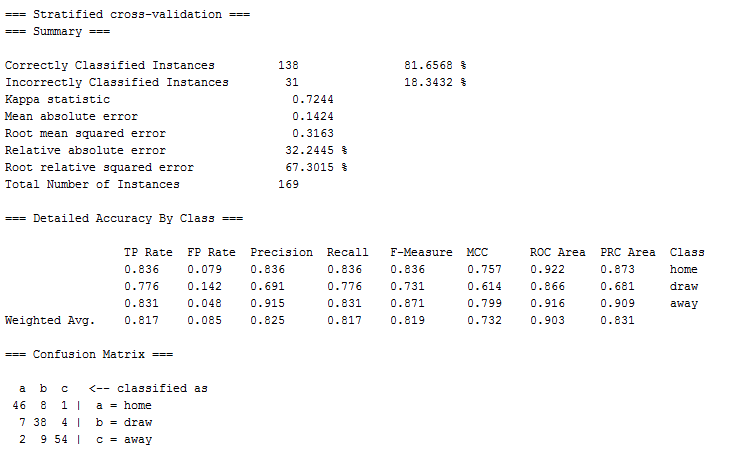
今節 実戦においての予測精度はおそらく60%ぐらいはあると考えているのですがどうでしょうか。 7/11 ぐらいの正解があれば それなりに成功かなと考えています。
結果検証
J2 17節 終了しました。結果は 4枠成功。ダメでしたね。期待したおよそ60%の正解率には到達できませんでした。ちなみにクロスバリデーションの数値は 正しい数値 ・・・つまり、実際の試合におけるパフォーマンスを入力して結果を予測させた場合、どれくらい正しく判断できているか? を示すものです。この状態でおよそ80%ぐらいは正しく結果を判断することができるというわけです。
なぜ 大きく期待値を下回るのか?
それは 正しい数値(実際のパフォーマンス)を入力していないからに過ぎません。しかし正しい数値 つまり、まだ行われていない、これから示すであろう実際の試合のパフォーマンスを正しくデータに入力して予測させることは不可能です。僕がやっていることは、直前に行われた試合で示されたパフォーマンスを仮のデータとして流用、代用して予測させているだけです。
問題の本質は 予測スキームやアルゴリズムにあるのではなく、データそのものにあります。そこを解決しなければ予測精度の向上は見込めないかもしれません。


コメント