
やはりディープラーニングは有能かもしれない。
対象物の特徴を捉えることに優れる ディープラーニング。私もブレークする前から注目していまして、無学ながら独自解釈で断片的にウェブ資料などをあさって自分なりに触れてきました。
世界的に見れば、このディープラーニングをサッカーの勝敗予想に使うというアイデア、どこかの優秀な人物がもうすでにかなりのところまで研究されてるのではないかと思います。サッカーに限らず、スポーツ科学の世界では、もう当たり前のように使われることになると予想されます。
さて、いろいろと説明変数をいじくって考えてきたサッカーの機械予想、しばらくはディープラーニングから離れて GBM というアルゴリズムに絞って予想をしてきました。今回の記事では、ふとした思い付きから、ディープラーニング において、説明変数をいじったらどうなるか? ということについて書いてみます。
トレーニングデータは累積タイプのものを使う。ただし説明変数については少し除外する。
これまでの経緯から、シュート関係の変数については除外したほうが良いものがあると考えています。どの属性を除外するか? は、アルゴリズムのタイプにも依存すると思われますが、シュート関係はそれだけでラベル(結果)を決定づけてしまうので注意が必要です。今回のテストにおいて除外した属性は以下です。
1、枠内シュート数
2、PKシュート数
3、シュート成功率
4、PK成功率
以上4個です。これらを除いた今季の累積データを使用しました。予測スキームは、H2O-3 で、ディープラーニング の rectifier を使用しています。グリッドサーチなどパラメーターは一切いじりません。初期設定のまま走らせます。
テストデータ には、直前のリーグ戦スタッツを今回の予想組み合わせに差し替えたものを使います。たとえば広島なら前節相手は鹿島でしたが、そのスタッツを今回の 柏ー広島 で使うというように。こうして予測させた結果は以下のようになりました。
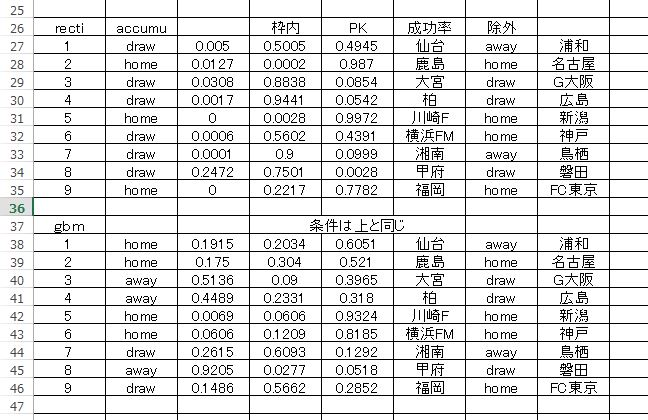
上の段がディープラーニングによる予測です。左から二列目が予測、右から二列目が実際の結果です。表の上に 予測条件のメモが書かれています。意味は 使われた分類器、そして累積データを使ったこと、最後に除外した属性が書かれています。
同じ条件で予測をさせましたが、GBMと比較して明らかにディープラーニングのほうが良い予測をしています。仙台―浦和 に関しては結果的にハズレとなっていますが、これを偶然とみるか?
全体的に見てもほんとに良い予想をしていると感じます。これって偶然?


コメント