

ズボラデータでどこまで正確に予測できるか?
今回は 「簡単に素早く正確に予測する」 というコンセプトで予測します。これまでいろいろデータをいじくって考えてきましたが、どうにも成果的には割に合わない結果ばかりでストレスが溜まっています。
できるだけ少ない労力で最大の成果を得るための予測方法を書いてみます。もちろん裏付けのない方法では意味がありませんので、それなりに検証はやっているという前提ですよ。
作業工程 その1 データ作成
今回の例では ファンタジーサッカー研究所 を使用します。
対戦成績 というタブから 対象とするホームチームの直近50回の試合結果をコピーします。それをエクセルでCSV保存します。
データに空白行(PK試合とかで空白ができる場合がある)があると悪影響がでる恐れがありますので、ちゃんとチェックして削除してください。以下の例においては空白がある状態で作業を続けています。ご注意ください。
例として 浦和ー柏 第25節 を載せます。
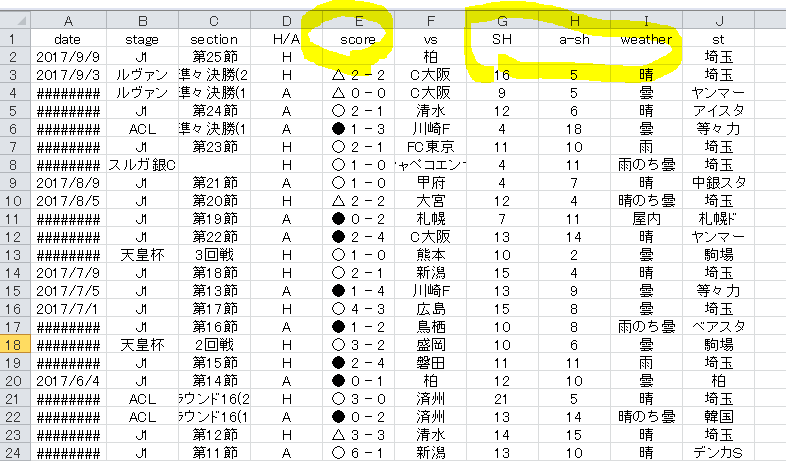
こんな感じ。ほとんど加工はしませんが、「詳細」などの不要な列、属性は削除してあります。属性名は日本語のままでも構いませんが、機械学習プラットホームに読み込ませると文字化けして見づらくなるので半角英数表記にした方が良い。
データの中身も文字化けしてしまいますが、アルゴリズムには影響ありませんのでこのまま放置していいです。
最後にちょっと面倒なのですが、コピーしたデータの最上段にひとつ空白行を挿入します。ここに予測対象とするデータを手打ちで入力します。画像の黄色マーク部分は空白となりますが、これはそのままでいいです。
日付と試合のタイトル、そして対戦相手、最後に会場を入力します。これがテストデータ部分になります。データの構成はトレーニングとテストデータがひとつにまとまった形状となります。
以上で準備完了です。これを機械学習プラットホームに読み込ませます。
作業工程 その2 パース時のエディットについて
機械学習プラットホームは H2O AI を使用する前提で話を進めます。
データ読み込みに成功すると以下の画面になります。ここでそれぞれの属性をチェックします。
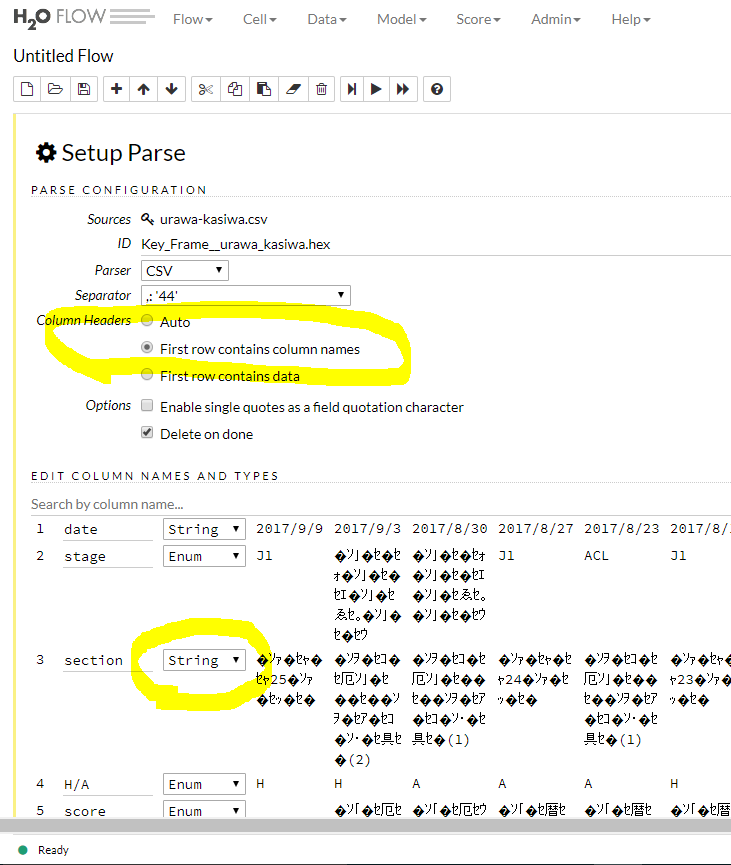
黄色マーカーの上の部分、First row contains column names という箇所にチェックが入っていれば自動的にカラムの名前が示されます。しかしこれがチェックされていない場合がありますので、必ず入れるようにしてください。
つぎに属性タイプを変更します。基本的に何もしなくてもいいのですが、一部については変える必要が出てきます。これはデータによってまちまちですので必ずチェックする必要があります。
上から二つ目の黄色マーキングは「変更すべき箇所」 を示しています。
画像では分かりにくいので以下に示しておきます。
- date string
- stage enum
- section enum
- H/A enum
- score enum
- vs enum
- SH numeric
- a-sh numeric
- weather enum
- st enum
すべてのデータにおいて、上のように属性を直してパースします。
作業工程 その3 予測モデル作成とPREDICT
H2Oフローからモデルタブを押して、GBMを選択します。先ほどパースしたデータをトレーニングデータとして選択、レスポンスカラム に score を選択します。
その他のパラメーターは基本的にいじりません。画面をずーっと下にスクロールして ビルドモデル をクリックします。インジケーターがオレンジからグレーに変わって100%になったらモデル作成完了です。
修了したらヴューを押します。
モデルの詳細が示されます。以下のような感じ。
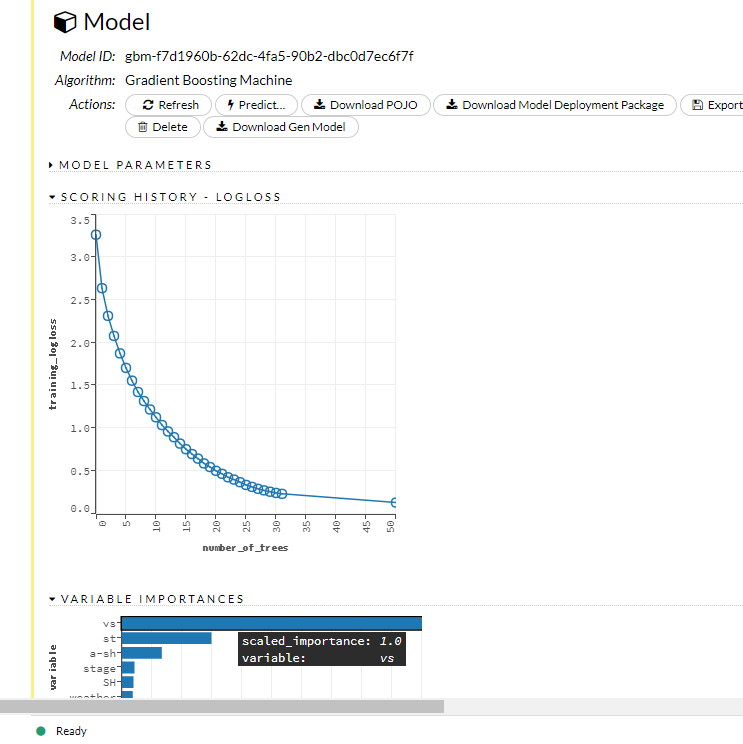
次に行うことは PREDICT です。これは上の画像の一番上、PREDICT タブをクリックします。そこでもう一度、トレーニングに使った同じデータを選択し、PREDICT させます。
ACTION ボタンを押すと以下のように結果が示されます。
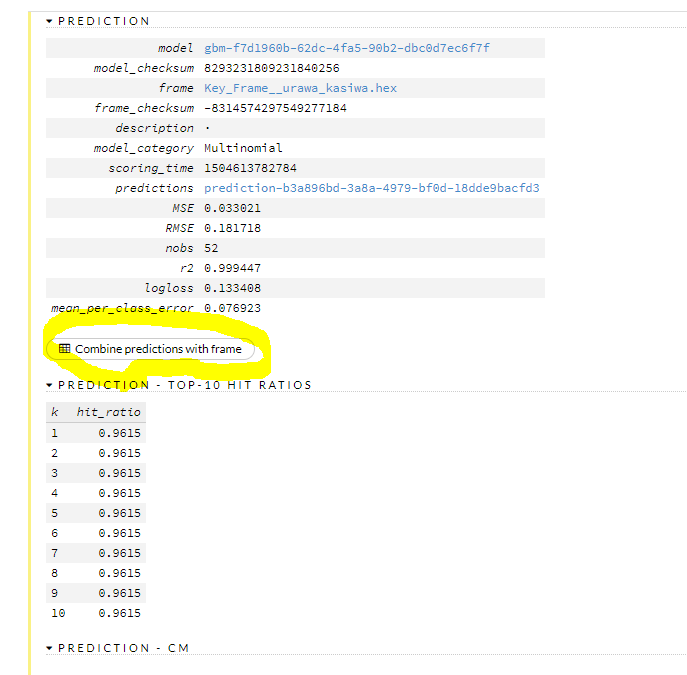
最後に上の画像の黄色マーク箇所をクリックします。そしてヴューフレームボタンをクリック。
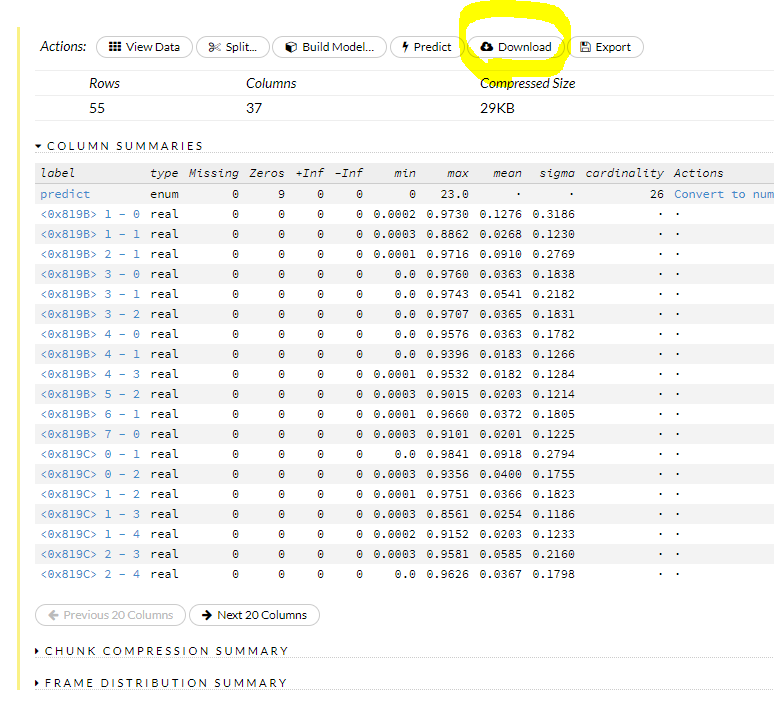
上のダウンロードを押すと、エクセルが開いて予測結果が最上段に示されます。エクセルにダウンロードしなくても 上のヴューデータタブを開いても確認できます。
予測結果を確率順に並べ替えたりするならダウンロードした方が作業はやりやすいです。ちなみに以下の画像は 浦和ー柏 25節 をこれまでのやり方で実際に予測させた結果です。エクセルにいったんダウンロードした後、データを並べ替えて確率順にしたものです。
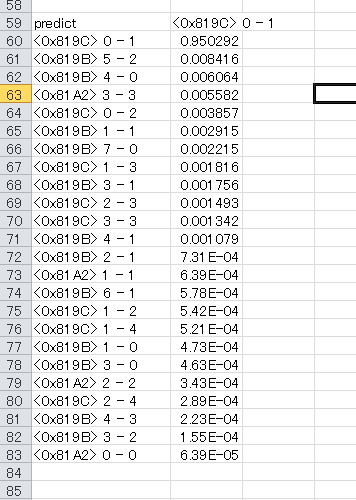
1-0 で柏の勝利か? あるいは浦和が勝つか? 確率的には圧倒的に柏の勝利かなといった予測結果ですね。当たるかどうかは知らんけど。
今回はこんな感じで予測します。残りの枠については後日追記しますね。
j1-25 j2-32 の予測
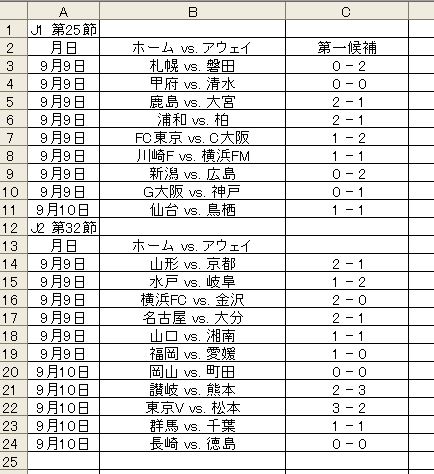
上の予測はすべてこのページに書いてあるやり方で予測したものです。第一候補と書いてあるのは分類確率の順位で一番確率が大きいものを選んでいます。スコアそのものはまず当たりません。勝ち負けとか引き分けかといったことぐらいしか判断できないです。
スコアを直接予測するためには
スコア部分を予測するためにはスコアデータ部分を分解して新たにカラムを増やしたり、別のデータソースから目的変数となるデータ・・・たとえば枠内シュート数とかその成功率などを取ってきてデータ構成を変えたりします。そして回帰とか分類などアルゴリズムも適切に変えて予測します。
検証のためにはこれらの作業を枠別に毎回行う必要があります。思いつく予測のためのアイデアというのはいろいろあるのですが、やはり何といっても継続作業に伴う面倒臭さというのがネックになります。
気合を入れてデータを作って予測しても、ハズレが頻発することはしばしばあります。テストしてハズレの繰り返しが続く。正直言ってやってられないです。
だからできるだけ簡単な作業で比較的正確な予測ができる方法を考えてるわけで。あとは試合の結果待ち。結果を見てまた考えましょう。
あ、例として挙げた 浦和ー柏 については空白行を削除した結果、浦和勝利 が第一候補に変化しました。やっぱりコピペした後にちゃんとチェックして整形しないとダメなようです。
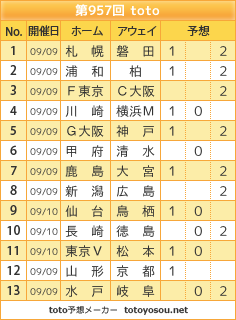
第957回 トト予想 第二候補も含めたマルチ予想
このページに書かれた方法で予測した第二候補も含めたマルチ予想です。すべての正解を含めることができれば成功ですが、おそらく無理じゃないかと思いますね。
予想について感想とか
最後に提示した マルチ予想 について評価してみます。
全体での正解は 9/13 でした。ダブル9 という比較的大きな網をかけた割には収穫が少ないですね。とりわけJ2において長崎や東京Vの枠をダブルで外したことが痛い。
結構自信はあったんですが、やっぱりこういうケースは起こるんですよ。これはアルゴリズムを変えても同じこと。やっぱりダブルでもハズレというのは発生する可能性は高いです。
甲府や新潟の枠も外していますが、こちらはシングルなので、まあしょうがないなぁという感じ。無理やりダブルになるまで結果を掘り下げれば拾えたかもしれません。
今回の予想はすべてGBMというアルゴリズムを使用したわけですが、アルゴリズムを変えてテストしてみたところ、全体的な正解率とか傾向もよく似た感じで、いずれもパーフェクト予想とはならず。
パーフェクトといってもダブルで収めるだけのことなのですが、これが本当に難しい。何か方法を考えて次回も挑戦します。

コメント