
大量データで予測する。ディープラーニングでごちゃまぜデータを予測させる。
過去5年分プラス今季直前までのデータをカテゴリーを混ぜてトレーニングデータとしました。いろいろデータ構成の組み合わせを試している段階ですが、「これが一番」 というように、簡単に判断することはとても難しい。
予想は二種類あります。どちらもH2Oのディープラーニングです。違いはEPOCHの回数の違いと、それに伴う活性化関数です。
かなり結果が割れているので判断が難しいですね。とりあえず単純比較で様子を見てみたい。
マイナス数値はホームの負け、ゼロは引き分け、プラス数値はホーム勝ちです。918回ゴール2 は事故みたいな試合じゃなきゃ両チームともホーム勝ちでしょう。
ガンバー広島 3点差、もしくは1点差、浦和ー仙台は 2点差 かな?
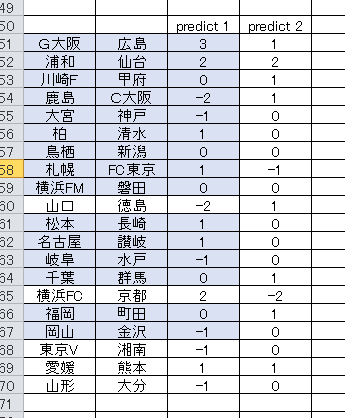
繰り返し学習回数(EPOCH) と 活性化関数
PREDICT 1 は、学習回数が 100 です。PREDICT 2 は、10の設定でしました。この設定で活性化関数をグリッドサーチしますと、それぞれ最も良い数値を示す予測モデルが示されます。
単純に考えると、学習回数が多い方が良いように思われますけど、これはいわゆる過学習状態。トレーニングデータに対しては良いけど、未知データの予測にはぜんぜんダメ・・・というヤツです。たぶん。
というわけで、自分としては PREDICT 2 の方が良いんじゃないかと思う。結果を見てみなければ何とも言えませんが。
点差による分類予測から優勢なチームを判断するやり方
一つの方法として次のように考えてみます。
これまでは 3WAY方式 によって分類予測をしていました。これはトレーニング状態から3WAYで学習し、そのまま結果を返すやり方でした。今回考えた方法は、まず点差を分類予測し、その結果からホーム側、それからアウェイ側それぞれの確率を合計して優劣を判断するという方法です。
ゼロ判定を挟んで、いくつかのゴール数分類確率が並びますが、これをマイナス側、プラス側それぞれ足し算するだけの簡単なものです。
この数値を比較します。以下が今回の計算結果となります。
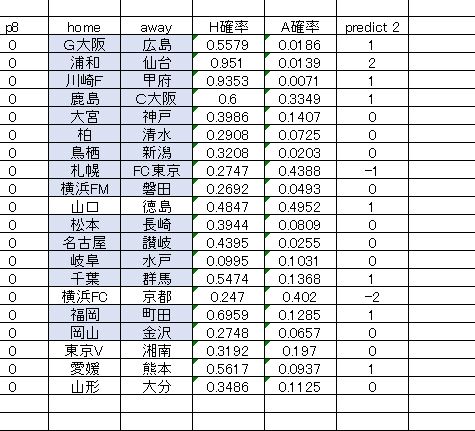
この方法は、前節でも試したのですが、そこそこ良い感触が得られたので今回も採用してみました。完璧に勝敗を捉えることは難しいですけど、そこそこ良い結果が期待できるんじゃないかと考えています。たぶん3WAY方式による分類確率よりは高精度で予測できると思う。
* 記事中、PREDICT 1、2 が逆になっていました。(訂正済み)1 は EPOCH 100、2 が 10回です。管理人のおすすめは、10回の PREDICT 2 です。数値はゴール数を示しているので間違えないでください。プラス符号(付いてないけど)は、ホームの勝ちという判定。マイナスはアウェイ勝ちです。
追記 日付データをDATE関数で整形した後、DLで予測させてみた。
これが最終予測。生データをいきなりH2Oに読み込ませずに、いったん日付関係属性をDATE関数でまとめます。それからH2Oに読み込ませてDLで予測させました。
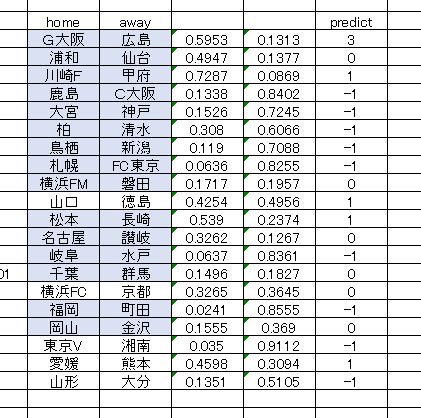
私は、こっちの予測が好み。当たるかどうかは知らんけど。 結果を見てまた考えます。
結果と感想
総合的に見て、かなり良い予測ができてると思います。
意外だったのは 学習回数 についてです。ディープラーニングにおいては 適切な学習回数 に設定することによってかなり予測精度が変わるのは間違いないです。
実際の試行においては、かなりマシンスペックに依存する部分があり、比較検討するにはじゅうぶんな時間をかける必要があるかと思います。データ量や属性数を増やして、グリッドサーチをかけるとものすごく負担が大きくなります。
今回の予測についてまとめると次のようになります。
1、トレーニングに使用したデータ
J1,J2,およびルヴァン杯の過去5年分のデータ プラス、今季直前までのデータ。J3 は除く。
2、アルゴリズム
H2O ディープラーニングを使用
3、繰り返し学習回数
100 もしくは 10
4、活性化関数の選択
グリッドサーチによる自動選択
5、日付データについて
生データをTIME属性とする。もうひとつは、DATE関数で整形後、TIME属性としてパースする。
6、点差分類を基本として判断する。分類確率による勝敗判断も有効。
次回もこの方法を試してみます。
追記 超びっくり!! テストの結果・・・
詳細は明らかにはできませんが、驚きのテスト結果が出ました。
*画像は削除しました。
一部を除き、ほぼ完璧に結果を捉えています。間違えているのは 山口ー徳島 のみ。あとは点差予測こそ一部違うものの、勝敗に関してはパーフェクトで予測できています。
自分でも、「何かの間違いじゃないか?」 と思って、データ漏洩などがないか確認してみたのだけど、確かに使用したのは今回の予測用データファイル。最初に使用したものと同じものでした。
アルゴリズムの設定を少し変えるだけでこれほど劇的に出力が変わるものなのか?
これが今後の予測においても通用するのであれば、恐ろしいことになる。
どうやら検証テストのやり方が間違ってたようです。このような予測結果が簡単に出せるわけない。やはりというか、データの漏洩があったようです。
追記2 同じやり方が通用するほど甘くはない。何かが違う。
過去の違う開催回についてもテストを繰り返しています。
結果から言うと、「とても良い結果を残したのと同じ方法で予測しても、同じように良い出力は期待できない」
それが良い方法であることは間違いない。偶然とか まぐれ というのは絶対ない。上に挙げたような パーフェクトに限りなく近い予測 というのは まぐれじゃ絶対出せません。
「簡単に出来るというなら、やって見せてほしい」
だけど何かが違う。どこかを変えて最適化しないとダメなような気がします。それを毎回しなければいけない。たぶん。
トレーニングデータは毎回更新される。だから毎回モデルを作り直す。アルゴリズムのチューニングの話なんだけど、それがどこなのか? 何なのか? 何をどう最適化すればいいのか?


コメント