

凡人の考えるアルゴリズムとデータの関係
凡人とは、僕のことです。あなたや、他の誰かではありません。
ふだんやっていた方法では、どんな予測結果が得られたのか?気になったので、ちょっとやってみました。
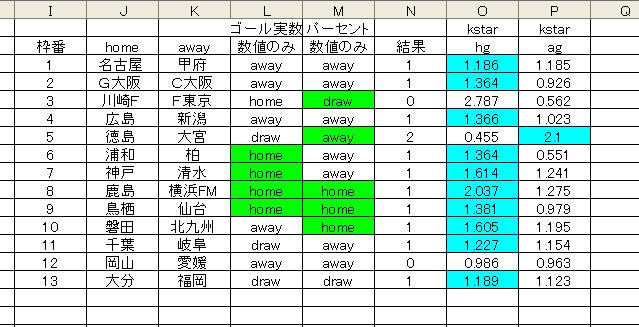
ブルーマーキングが普段の予測結果です。
11/13 が正解しています。これは単純に予測数値を比較しただけです。
数値の大きいほうが、単純にゴール数が大きいという意味です。
kstar はアルゴリズムの名前。
与えた属性は以下。
- スタジアム
- home
- away
- ゴール数
これを、ホームチームのゴール数、それからアウエイのゴール数と別々に算出します。表の場合、ゴール数はそのまま numeric として計算してあります。これを nominal として計算すると、また別の結果が出力されます。(引き分けとして出力される枠もある)
データ量は今季の最初のリーグ戦からです。それを比較するだけです。
KSTAR は ”過去ベース推論” ですので、だいたいは支持率なんかと同じ傾向を吐き出します。人の目で未来傾向を考えた場合、過去の傾向を参照することはごくフツーの感覚ですので。
KNN も、おなじようなアルゴリズムで良いかも。(K近傍法)
したがって、今回のような結果になると、ものすごく配当金が低くなります。
kstar の長所は、順当結果に強いというところ。
なので、全体の傾向を知るには、良いアルゴリズム です。
データ量が極端に少ないときに適しているアルゴリズムは?
僕のなかでは MLP なんですけどね。。今回もそうでした。しかし結果が付いてきません。原因はなんとなくですが分かっています。
マルチレイヤーパーセプトロン MLPは傾向が同じような時は良い結果を示す。たぶん。
バックプロパゲーション(Backpropagation)または誤差逆伝播法(ごさぎゃくでんぱほう)
ご存知のように トトくじ は毎回傾向が違います。正確にいうと、順位の上(強いチーム)が必ず勝つわけでもないし、逆もそうです。だから MLP のように誤差を最小にする重み付けを行って予測しても上手くいかない。
これは他のアルゴリズムでもそうです。おなじ条件で継続するようなデータ、たとえば自然分野での分類とか、企業などのお客の行動、属性の分類などは、もっと精度が高くなると思います。
つまり、観測するたびに結果が(分類が)変わるデータは予測がむずかしいということ。統計的というか頻度でいうと勝つことが多いから、そうなる確率も高いのだけど、実際、つぎの試合もそうか?というと「そうでもない」
ここがむずかしいです。
やっぱりデータ量は多くあったほうがいい
まあ、おもしろくもない見解ですが、データの量は多くあったほうがいいです。
今回は、わずか過去1節のみの情報で予測させてみたわけですが、もうすこし得失点パターンと結果の比較データがあれば良い予測ができたかもしれません。
引き続き観測したいと思います。

コメント