
H2Oにおいては Distributed RF: Create a distributed Random Forest model. と表記してあります。分散型 という意味でよいと思うのですが、これで検索してもぴったりなものがヒットしません。イメージ的には、たくさんの分類構造(決定木)の寄せ集め的な感じがするランダムフォレスト。
自分なりにいろいろ試した結果を記録しておきます。チュートリアル的なものは書きません。トト、サッカーの勝敗予測に特化した記録です。
ランダムフォレストのもっとも良い設定はどうすればいいのか?
予測の精度は与えるデータ構造に大きく依存するのは間違いないです。これまで長い時間をかけて自分なりに考えてきましたが、ここが一番の肝かもしれません。アルゴリズムについて考えるのも重要なのですが、それらはデータ構造と比較するとそれほど重要ではない気がします。なぜなら予測精度の高め方についての情報は豊富にあるからです。
逆に、ある事象の予測に特化したデータ構造の作り方については まったく情報がない といってもよい。
ちょっと話がそれてしまいました。
一時はディープラーニングに飛びついていましたが、サッカー予想に特化した場合、ランダムフォレストがもっとも予測に適している感じがします。いくつも並べられた属性、変数をサンプリングしてたくさんの決定木をつくり、それらを森として最終的に判断を下すモデルです。
以下に実際に H2O で作成した予測モデルを挙げておきます。対象事例は J1 における 第4節 の勝敗予測です。
予測モデルに使用したデータは 第1節から3節までの情報を自分なりにまとめて構造化したものです。
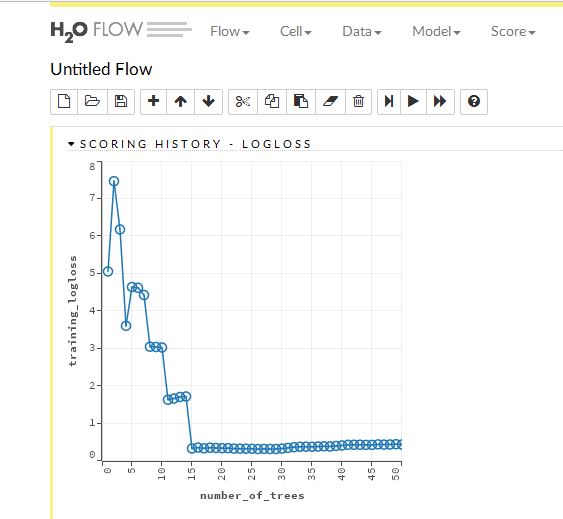
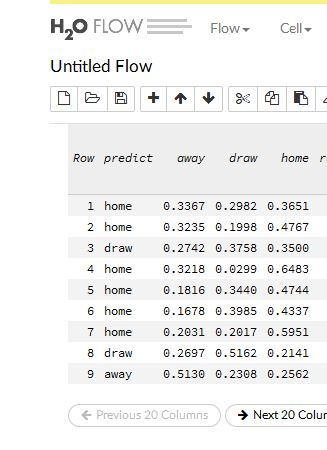 実際の結果は以下です。
実際の結果は以下です。
| 横浜F・マリノス | 2 – 1 | サガン鳥栖 |
| ヴァンフォーレ甲府 | 0 – 4 | 川崎フロンターレ |
| アルビレックス新潟 | 2 – 2 | 柏レイソル |
| 名古屋グランパス | 2 – 1 | ベガルタ仙台 |
| 鹿島アントラーズ | 2 – 0 | FC東京 |
| ヴィッセル神戸 | 2 – 1 | ガンバ大阪 |
| ジュビロ磐田 | 2 – 2 | アビスパ福岡 |
| 大宮アルディージャ | 1 – 5 | サンフレッチェ広島 |
| 湘南ベルマーレ | 0 – 2 | 浦和レッズ |
以上が 第4節 J1 における 自分なりのベスト予想です。予測がミスっているのは全部で3枠。甲府―川崎、磐田―福岡、大宮ー広島 の3枠です。磐田 以外は単純なミスのように見えます。直感によるアナログ予想では まずこのようには予想しないと感じます。
なぜ間違えて予測しているのか? 他の枠は上手く予測できているのに。今後の予測においても こういったケースが出てくる可能性は高いです。なんとか予測のズレを修正できる方法を考えたいですね。
ランダムフォレストの設定で気になった箇所をいくつか残しておきます。
このモデルを作成するのにグリッドサーチは ほとんど使いませんでした。決定木の数とか深さ、それに属性選択数とかあるんですけど、初期設定のままでもほとんど問題はないと感じます。必要に応じてチェックすればいいと思います。データの規模にもよるので何とも言えません。いろいろ試してみるべきでしょう。
アドバンス や エキスパート のグリッドをいじる前に最低限のグリッドサーチは試すべきです。
一番気になったのは・・
Balance training data class counts via over/under-sampling (for imbalanced data).
という箇所。ADVANCE のグリッド項目にあります。
これは 正例 負例 とかいわれているものです。検索で情報は得られますが、要するにデータの内容が偏っていると、まともに分類ができなくなるという現象について書いてあります。これらの問題を回避する方法はいくつかあります。
H2Oにおいては、これにチェックを入れると、自動的にバランスのとれたダミーデータを作成して予測モデルを作成してくれるわけです。私の事例ですと、実際には18行のデータしかありませんでしたが、
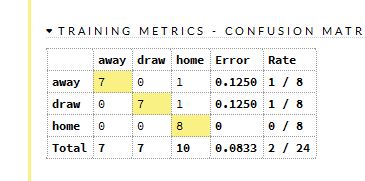
Training Metrics – Confusion Matrix vertical: actual; across: predicted
を見てもらえば分かるとおり24行のデータでエラー率を計算しています。バランスをとるために6行のダミーデータを作ってくれているのが分かります。この機能はかなり使えるんじゃないかと思います。最初は意味も分からずやっていたので 「なぜデータと合わないんだろう?」 と思っていました。バカですね。
もう一つチェックしたところはモデル作成の最終行にある Cartesian という言葉。これはグリッド機能を どれかひとつでもチェックすると現れるチェックボックスです。
Cartesianとは デカルト派というか解析幾何学というか、いわゆる座標ですべてを表現することを表わす言葉のようです。イメージとしては なにか 「カチッ」とした分析手法を想わせます。一方の ランダムディスクリートはハイパーパラメータのすべての組み合わせを探索、最適化してくれるようです。
意味がイマイチ分かりにくいのですが、グリッドサーチ全体の考え方、働き方について選択する箇所であり、細やかな最適化を望むなら Random Discrete を選択したほうが良いようです。
以下工事中。


コメント