
まだ試作段階ですが、H2O の ウェブヴァージョン において簡単に予測モデルのパラメーターを最適化する手法について書きます。統計解析ソフトの R とか、 PYTHON を使う方法もあるのですが、現状でもっとも簡単な方法は以下です。
gridを使えば一番良い予測モデルを示してくれる
grid とは何か?
下の画像を見てください。
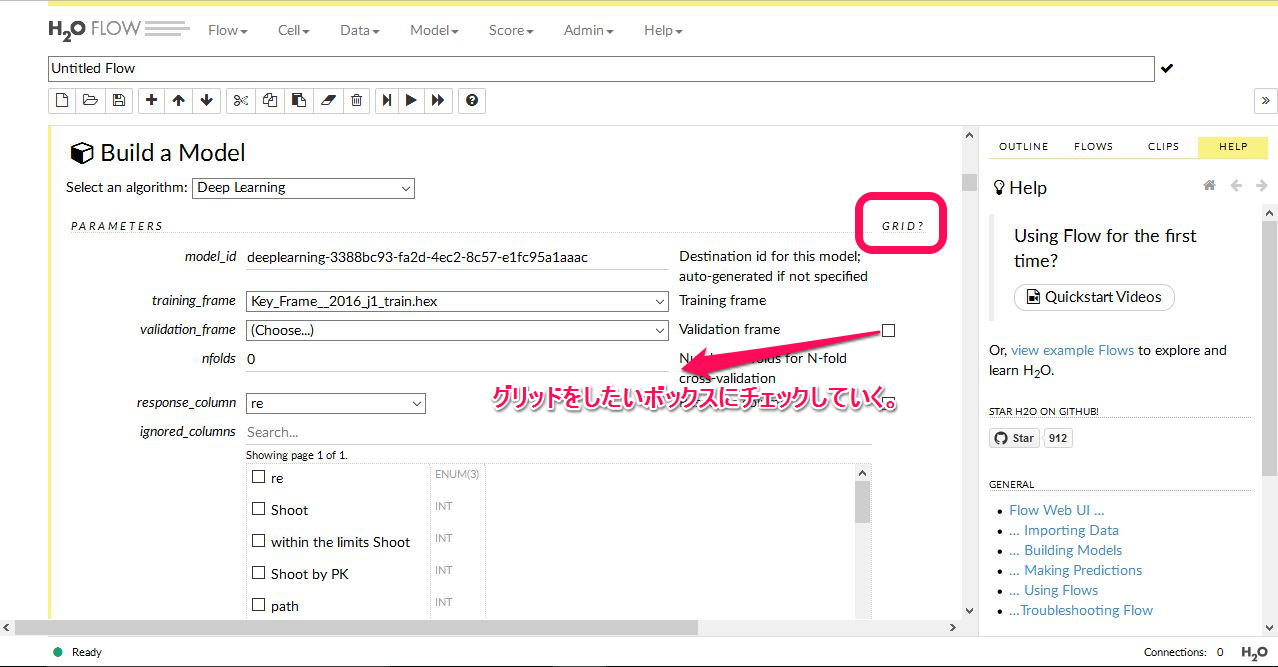
これは モデルにディープラーニングを選択したものです。赤枠で囲われたところに grid? とあります。最初はこれが何なのか? 分かりませんでした。結局のところ これは下にずらーっと並んでいるチェックボックスのことを意味していて、ここにチェックを入れると自動的にサーチをしてくれる という意味だったんですね。
モデル構築のヘルプには書いてなかったような気がするのですが、おそらくそういうことです。
試しに何でもかんでもチェックしてモデル構築を試してみたのですが、やはりエラーが出て止まってしまいます。何らかの規則というか制限があるようですが現状では理解できていません。
このパラメーター調整には ランク みたいなものがあります。具体的には Advanced 、Expert というように付けられています。そこで、そういう高度な調整はひとまず置いておいて、もっとも基本的な箇所だけチェックを入れてモデルを作ってみました。具体的には以下の箇所です。
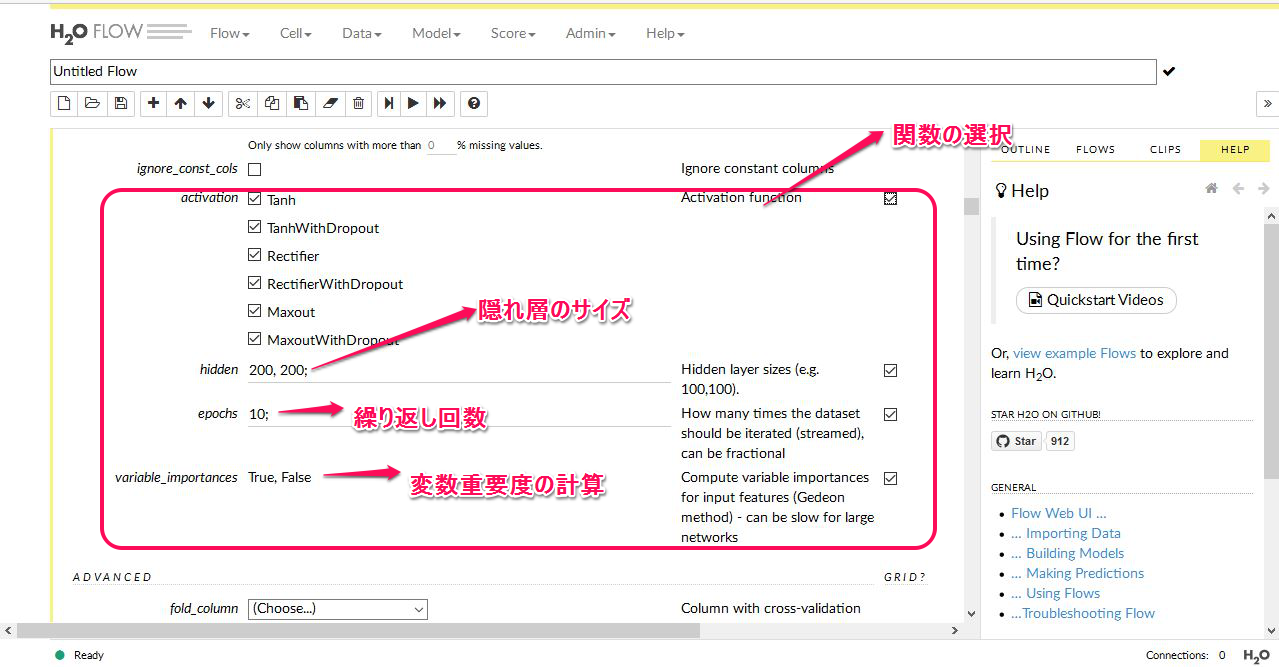 具体的にモデルを作成してみます。やり方は通常と同じで、モデルを選び、データを選択します。そして上のようにチェックマークを入れて・・・最後にある ビルドモデル をクリックするだけです。
具体的にモデルを作成してみます。やり方は通常と同じで、モデルを選び、データを選択します。そして上のようにチェックマークを入れて・・・最後にある ビルドモデル をクリックするだけです。
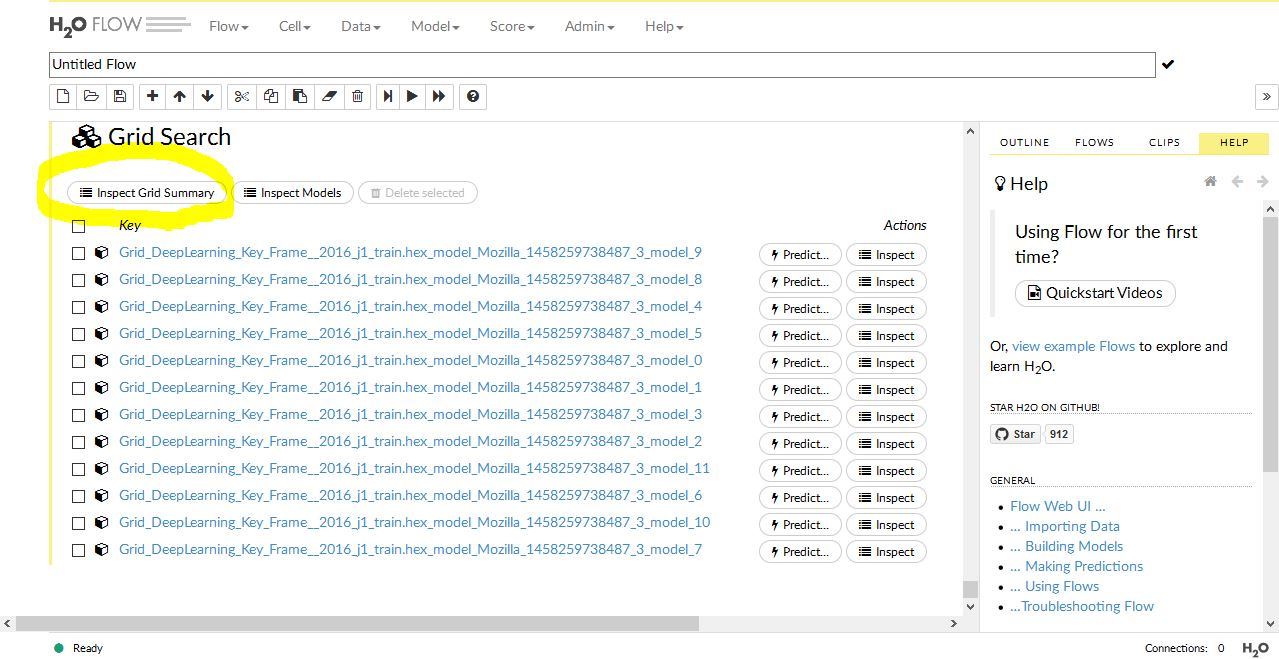
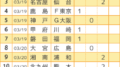
すると上のように 予測モデル がずらっと表示されました。このケースでは 全部で11個のモデルが作成されたようです。一番上に表示されるモデルが一番ピッタリくるモデルというわけですね。とりあえず全部のモデルについて詳細を見てみます。黄色枠で囲まれた INSPECT GRID SUMMARY をクリックします。
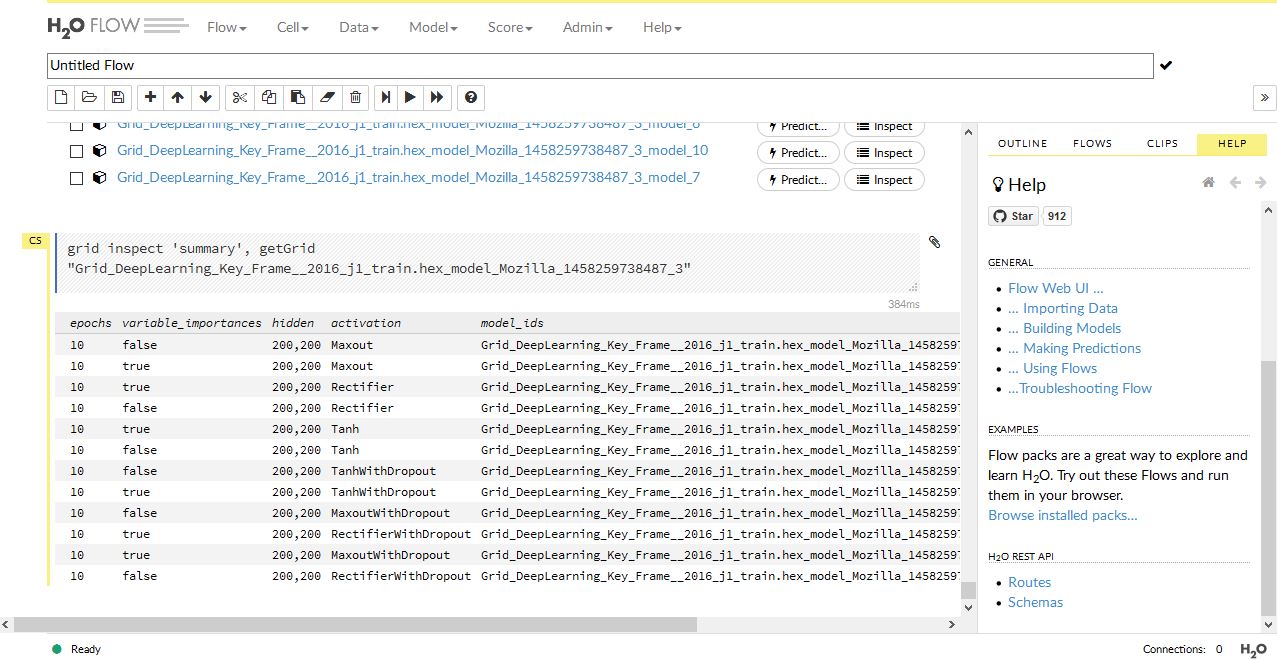
すると上のように繰り返し回数とか隠れ層ユニット数とか活性化関数の種類が表示されます。ちなみに画面下にあるスクロールバーを右に寄せると log loss の値が確認できます。
log loss とは分類問題における評価関数のひとつらしい。数式を見てもさっぱり分からないけど下のサイト情報を参考にしました。

次は この過程で得られたベストな予測モデルを使って実際に予測するだけです。その前にいろいろモデルを使って過去データに対する検証をしてみてもいいかなと思います。ただし僕がやっているケースでは経時変化がありますからベストモデルを使っての精度検証はむずかしいかもしれません。
よくある IRISデータ などは時間の変化によって花の形状が変わることは考えにくいので、いくらでも分類精度について検証できる。つまり同じようなデータなら時間が経過しても同じカテゴリーに属する確率が非常に高い事例だということ。
ちょっと話はそれましたが、引き続き より高度な性能アップを目指して勉強したいと思います。
グリッドサーチ機能を使うとモデル構築に時間がかかります。
基本的にグリッドサーチ機能を使えば使うほどモデル構築に時間がかかります。これはパソコン性能に大きく依存します。今僕が使っているノートパソコンは へっぽこ野郎 なんで、ディープラーニングのアドバンスグリッドサーチまでやろうとすると、とんでもないことになります。
できるだけ性能の良いパソコン環境をつくることが必要となります。
以下工事中。。
コメント