
第940回 トト予想はこれで
さくっと第一候補挙げておきます。
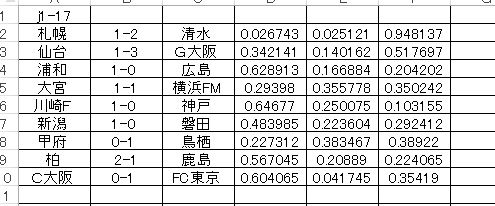
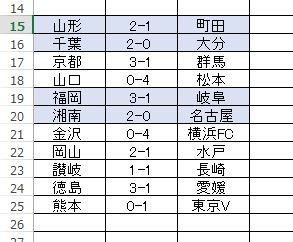
J1 の方だけ確率値出しました。算出方法は少し変わったやり方。だからスコア予測とは完全に一致していない枠もある。どうなるか?
試合結果と感想
札幌ー清水 だけ終わりました。のっけからハズレです。
なんだか嫌な予感はしたんですが、やっぱりでしたね。「ほぼ清水で鉄板だろう」 という思い込みは木っ端みじんに打ち砕かれた。いや、私の場合は機械予想でほぼ鉄板という目でしたからね、まったく疑う余地はなかったです。
じつはディープラーニングでも予想は出していまして、こちらでも第一候補は清水です。しかし出力を注意深く見ると以下のようになっていました。
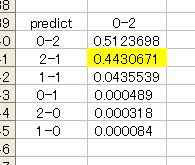
後だしじゃんけんみたいでイヤなんですけど、こういう結果を見るとディープラーニング予想もなかなか切り捨てられない。51%ほどで清水、44%ほどで札幌優勢という感じの予想ですね。
こういったこじつけみたいな再予測による検証というのはいくらでもやることができるのですが、開催回ごとに全く違った傾向があって、統計的にああだこうだと言っても上手くまとまらない。やっても無駄といってもいいかも。
札幌ー清水 に関しては、ナイーブベイズ的アプローチでは 「ほぼ予測不能であった」 と言っていい。
さて、初日がすべて終了したので、上にあげたナイーブベイズによる予測の全体的な評価をしてみます。
J2から。 スコア予測の勝敗部分だけみます。全体的にみれば 「合ってる」 という感じ。一部、真逆の予想となっていますけど。11枠中 4枠の誤りということで評価としてはやっぱり微妙なのかなぁ。
J1についても同様で、合ってるようで合ってないという微妙な感じ。札幌や新潟なども落としているし、マリノスも微妙。
ナイーブベイズはある程度は良いと思ってるんだけど、属性タイプの設定によってはまったく機能しなくなる。基本は名義属性のみでデータを構成する必要がある。
たとえば時間属性や数値などの連続値タイプ、そして試合会場、チーム名、人名などの名義属性を混在させたタイプのデータでは上手く機能しない場合がある。
アルゴリズムを評価する際には、データタイプも考えないとダメです。ちなみに予測表にある結果は一部を除きすべて名義属性に変換して走らせたもの。予測モデルの評価関数の数値は非常に悪くて、まず 「普通の感覚で判定するならば」 おそらく使わないレベルの出来損ない予測モデルと言えます。
それを分かったうえで、あえて使用しているのは 「出力結果のみ」 に注目しているからです。通常の意味で良い予測モデル(評価指数が非常に良いモデル)でも結果が伴わないものは使わない。
データタイプ 属性タイプの設定について
H2O AI におけるアルゴリズムタイプというのは限られています。多くても3、あるいは4つぐらいしかないです。この中から目的に合わせて選択します。
計算の結果、思わしい結果が得られなかった場合、原因をどこに求めるか?
私がいつもやってることはつまりはそういうこと。データ本体の構成であるとか、パース時の属性タイプ設定とか、あるいはアルゴリズムのパラメーターいじりとか。それらもろもろの組み合わせからベストな予測モデルを見つけ出し、完璧な予測をすること。
まあ無理っぽいと言ってしまえば簡単なことなんですけど、現在注目中なのが 「属性タイプ」 なんですね。これを変えるだけで結果が変わる。
たとえば 年度 という属性を付けてみることを考えてみます。2017 は連続値、ただの数値にも見える、もちろん 年度 というようにも見える。時間なのか数値なのか、あるいは名義なのか?
節 についても同様、周期的なサイクルを持つ時間属性とも考えられるし、あるいは名義属性としても捉えられます。
一見すると何の関係もないような属性も重要な意味を持つ属性となる可能性がある。まだまだ時間もかかりそうですが、試行を繰り返してみるしかない。


コメント