
第887回 トトくじ予想 新しいデータフォームで挑戦
前回 886回トトくじの結果は、9枠正解が最高でした。平凡です。。気を取り直して予想に取り組みましょう。今節は J2全部 と、J3 2試合。データフォームを以前とはガラリと変えて臨みます。大きな違いはトレーニングデータをホーム側とアウェイ側というようにふたつに分けて予測する点。当然ながら1枠に対して出力はふたつになります。それぞれが違った結果ならダブルとなります。
枠ごとにアルゴリズムを変更する案はいまのところ保留。ランダムフォレストやナイーブベイズで第二候補まで絞るやり方も保留です。保留の理由は、必然的に母体数が大きくなって絞り込みが難しくなるることがまず一点。二点目は、第二候補まで絞ってしまうことにより、取りこぼしをしたまま予想案を固めてしまう弱点があることです。
まあ、どのみちハズレというのは取りこぼしと同じことで、どんな予想のやり方にしろ発生する可能性はあります。重要なのは 「正確な予想を可能な限りすること」 なのでシングルであれマルチ多用であれ全部の正解を予想案に含めて入れさえすればいいわけです。当たり前のこと言ってるだけですが。
というわけで、今回の機械予想です。

一番右側の数字が予想となります。ダブルは7個。多いですね。実際には削減すると思います。札幌、千葉、東京V あたりがマークがないですねー。。ちょっと不安な予想という感じがします。たまには人力予想で勘でマークしたやつを入れてみようかなとも思いますね。
どうしようかな。
第887回 トト 追加予想
試験的に追加予想を載せます。使用データフォームは先の予想と全く同じですが、アルゴリズムを変えて出してみました。すべての枠で同じアルゴリズムを使用しています。クロスバリデーション の結果はこちらの方が良いですが、それほど期待できるものではありません。およそ50%程度の正解率というのは、おそらく低すぎる。しかしその他のアルゴリズムによる正解率が30%程度であることを考えると、有意性はあるはず。最低でも6~7枠ほどは正解を含んでいるだろうと思います。
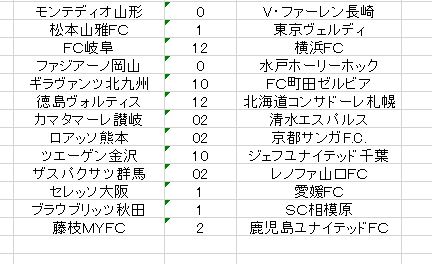
対戦組み合わせに応じて最適のアルゴリズムを選択するという方法
まだ試験中ですが、対戦カードによって 「クロスバリデーションの結果が変わる」 というのは事実です。ある対戦においては良い結果を示しているけれども、同じアルゴリズムを用いて他の対戦について交差検定を行うと、先の例よりは良い結果を示さないということはあります。
また同じアルゴリズムを用いても開催回によってはまったく使い物にならなかったというケースはこれまでも数多く体験してきました。これらのことから 「対戦カードには予想に際して最適のアルゴリズムがある」 と考える方が自然なのではないか。
これらのことを実証するには多くの対戦について、有効だと思われるアルゴリズム、予測スキームを用意して、それらの予測結果と実際の結果を照合する作業が必要となります。考えるだけでも気が遠くなりそうですが、やってみる価値はありそうです。
幸いにも WEKA には 「検証」 という機能が付いています。操作方法についてはまだ学習中ですが、おおよそ見当がついてきたのでいじっている最中です。ひとつのトレーニングデータに対して選択したアルゴリズムすべての交差検定の結果を一発で確認できるので効率的です。
あとは最適な予測モデルから導かれた予測結果と実際の結果を照合して何らかの知見を得る。これが現在の状況ですね。
第887回トト 最終予想はこれだ
いろいろ能書きたれましたけど、最終予想は以下のようになりました。

まあ順当な目が多くて、あんまりおもしろい予想ではありません。すべてWEKAを使っての予測です。アルゴリズムは枠ごとに個別に選定しているのですが、中心となるアルゴリズムというのは大体決まってくる傾向があるようです。今回は統計的なアプローチが強いので順当寄りな予想となっていますね。
分析結果で興味深かったのは J3 の二試合。特に 藤枝ー鹿児島 が奇妙な結果でどう判断したらいいのか、非常に迷いました。詳しくはちょっと書けないのですが、おそらくは鹿児島が優勢なんだろうと思います。さて結果は?
第887回トト 結果を見る
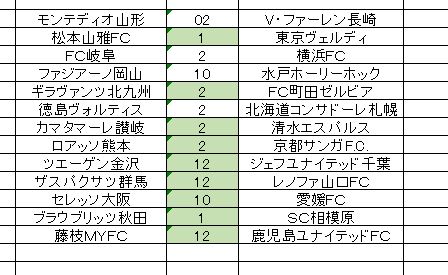 色付き枠は正解した箇所です。ダブル6 で9個の正解。費用対効果は悪いです。札幌と横浜FCの負けがけっこう波乱だったんじゃないかと。次に岡山の負けですか。山形ー長崎 はドロー濃厚でしたが最後に山形に軍配が上がると。
色付き枠は正解した箇所です。ダブル6 で9個の正解。費用対効果は悪いです。札幌と横浜FCの負けがけっこう波乱だったんじゃないかと。次に岡山の負けですか。山形ー長崎 はドロー濃厚でしたが最後に山形に軍配が上がると。
この予想は、アルゴリズムを最適化して臨んだ最初の形となります。最適化 というと大げさですが、要は一番良いと思われる予測モデルを選択しただけのことですね。ホームとアウェイ別々にモデルを選定しているので出力が異なれば必然的にダブル予想となる仕組み。まずはそれほど大スベりしなかったんじゃないかと思います。ほぼ順当なところは押さえてあると思うので当然か。ただそれが上手くはまらなかったですね。はまればはまったで、配当の低いまったく面白くない予想となるのですが。
とりあえず 最適な予測モデルはどれか? という課題はちゃんとした分析結果から導くことができる。未知のデータに対しての予想正確度は分からないけれども、クロスバリデーションの結果からはおおよそ判断ができます。
トレーニングデータの形式というか、フォーマットを変化させれば、それに伴って同じアルゴリズムでも交差検定の結果は変わりますので、違うデータフォーマットでも試行する必要がありますね。
どんなデータフォーマットが一番しっくり来るか? これを検証するにはとても手間がかかるし、評価の方法すら思い浮かばないです。問題点を整理すると次の二点になるか。
1、アルゴリズムのポテンシャルを最大に引き出すデータとはどんなデータか?
2、トレーニングデータに適した、もっとも分類性能の良いアルゴリズムを見極める方法とは?
基本的にアルゴリズムには優劣などないです。データや目的に対するマッチング次第で最大の効果を得ることができるはず。単純に考えれば説明変数と目的変数の相関が高いデータほど良い。
アルゴリズムの選定においては、クロスバリデーション(ブラインドテスト)の結果が良いものほど優秀。ただし
トト予想におけるアルゴリズムの選定には○○○○が重要かもしれない。
ので、単純にクロスバリデーションの数値の良いものを選んでも上手くいかないケースがあると考えます。


コメント