
10-fold クロスバリデーション の比較による予測スキームの選択
現在、トト予想に使用しているソフトは WEKA と H2O-3 のふたつ。いずれも交差検定する機能は装備されていて、その予測精度を比較検証することができます。今節は H2O-3 をメインに予測をします。
今回は Gradient Boosting Method を使用します。以下、交差検定の結果です。

各種パラメーターは初期設定のままでモデル構築を行っています。ディープラーニングなどその他のアルゴリズムも試してみましたが、上のモデルのほうが良い結果を残しています。パラメーターの設定によってはもっと良くなるかもしれません。
DRAW のエラー率が比較すると高いですね。およそ半分しか正しく判断できていません。ちなみにデータ本体の数値部分(スタッツ)は実際の試合のものをそのまま記入してあります。実際に行われた試合のスタッツだけを見ても、引き分け については判断するのが難しいというわけです。
j1 16節 予測
つぎに、上の交差検定で得られた予測モデルにしたがって j1 16節 の試合結果を予測させたものが以下になります。
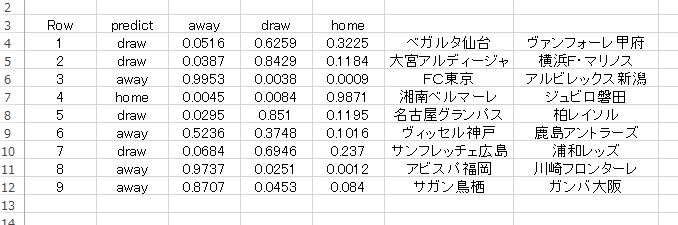
この予測で使用した テストデータ には、前節のスタッツを流用してあります。クロスバリデーションの結果は およそ80%の精度で予測できていましたが、それは 正しい実際のスタッツ を使用した場合の結果です。私の例のように 違うスタッツ を流用して予測した場合には、それが結果的に正しいスタッツとよく似ていた場合でも およそ80%ほどの予測精度しかない ことに注意してください。
実際には もっと予測精度が落ちます。良くても60%ほどではないかと思います。下手したらもっと悪くなるかもです。
J2 や、その他のアルゴリズムによる予測結果については追記の予定。
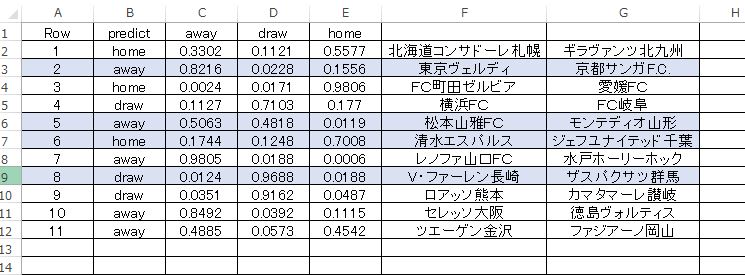
j2 19節 予想
J2 も H2O における予測傾向はおなじ感じです。細かい違いはあるのですが、比較の結果 J1 と同じ Gradient Boosting Method を使用しました。10-foldクロスバリデーションの結果は以下のようになりました。
 DRAW のエラー率が J1 と比較して良くなっています。と同時に HOME AWAY のエラー率が少しだけ悪化しています。全体としては およそ80%の予測精度という点では同じです。以下にこのモデルによる予測結果を載せます。
DRAW のエラー率が J1 と比較して良くなっています。と同時に HOME AWAY のエラー率が少しだけ悪化しています。全体としては およそ80%の予測精度という点では同じです。以下にこのモデルによる予測結果を載せます。
第854回トト予想 まとめ
今回 予想に用いた Gradient Boosting Method
パラメーター設定は すべてデフォルトです。いじったのはクロスバリデーションのみで、回数は10です。j1、j2 とも、変数重要度はほぼ同じであり シュート成功率がもっとも重視されています。さらに細かく言うならば、ホーム側のシュート成功率に一番重みがかけられています。J2 においても テストデータへは前節のスタッツデータを流用しています。考え方は J1 とまったく同じです。
予測を示した表の 確率の数値 にも注目してみてください。まったく予測がずれてる場合もありますので過信は禁物ですが、ダブル買いの候補として考えることもできます。
結果検証
J1 終了しました。さっそく検証します。個別の試合内容については論評しません。まず全体の正解率について。4/9 で、かろうじて50%ぐらいの正解率となりました。ほぼ想定した通りとなっています。なお、ひいき目に見ての感想となりますが、確率に注目してみると第二候補までですべての正解を含んでいることに気が付きます。
非常に微妙な数値も含みますけれども、今回は上手くデータがはまったようです。以下に表にまとめてみました。

確率順列 というのは、最初に挙げた予測の away,draw,home という順番で並べられた数値を 大きい方から順にペアにしたものです。すべての正解枠を ダブルに収める というのは簡単そうで相当に難しい。いわゆる 最大予想母体にすべての正解を含める という予想のやり方なんですが、ダブルでハズしてしまうことはよくあることです。
目指すべきことは 最大予想母体ですべての正解を含める ということなんですが、その進化形、第二段階として 全枠ダブルによる完全予想母体の完成 という段階があります。そして最終的には その最大予想母体をできるだけ小さくコンパクトに(現実的に買える組み合わせ)として余分な買い目を減らすことにあります。ここがまだよく分かっていません。
過去の直接対決に注目してみる
今回は普段はまったくチェックしていない 過去の直接対決の結果 にも注目してみました。なぜ注目していなかったのか? それは 経年によるチーム状況の変化 があるからでした。しかしながらよく考えてみれば 多少の変化はあるにせよチームの中核となる選手というのはそれほど激しい動き(移籍など)はないのではないか? ということに思い当ります。チーム名などの固有ID、それ自体には数値的な意味合いはなにもありませんが、チーム戦術に影響を与える選手というのは必ずいます。そしてそれはチーム全体のカラーを特徴づけ、ほかの選手に影響を与え続ける。
たとえば 川崎 といえば 中村憲剛、マリノス なら ・・ ガンバ なら・・鹿島なら・・といった具合に。そういう観点から今回の結果を考えてみると 波乱 というよりは、ある程度予測できる結果だったのではないか。
たとえば 川崎のドロー。直近では福岡に負けています。ガンバも鳥栖に対してはあまりよくはありません。湘南の勝ちも意外ではないです。
これが今回の結果で得られた私にとっての新たな視点です。この要素を機械学習による分類予想に取り入れることは可能か? やり方のひとつとしては テストデータの数値部分に 直近の直接対決時のスタッツを流用してみる。ただのアイデア段階ですけれども試してみる価値はありそうです。
J2 については また追記予定です。
j2-19節 結果検証
J2 についての予測結果です。
J1 と比較するとまったく良くないです。クロスバリデーションの結果は似ていましたが、肝心の予想については かなり的がずれている と言える。注意深く観察すると、確率順列、序列でいう 第二候補でもハズシている枠がいくつかあります。つまり 惜しいハズレ方 ではなくて、まったくデタラメなハズレ方をしているように見える。悪く言えば 当てずっぽう のような印象を受ける。
なんでだ?
適当に理由を挙げてみるとすれば以下のような見立ても可能かもしれません。
つまり、J1レベル においては比較的戦力が均一化していて、対戦相手によってのレベルの差は小さい。だから前節スタッツをテストデータに流用しても それほど実際のスタッツとかけ離れることは少なく、割と安定した予測結果を得ることができている。
J2 においては逆で、チーム間の戦力のバラつきが J1 と比較すると大きく、したがって前節スタッツを流用した予測においては不安定な結果になることが多い。
以上述べたことは単なる思いつきなので裏付けはありません。しかしなんでこんなに大きな差を感じるのか?


コメント