
J1-6節 j2-7節 まとめて予想
今回のトトはリーグ戦が対象です。予想用のデータ(トレーニングデータ)は、すべて今季のものです。タイプは累積データとなり、1節からのデータを自分なりに再構成して使っています。予測に使用したアルゴリズムについては、J1 では ディープラーニング、J2 は、ランダムフォレスト となっています。
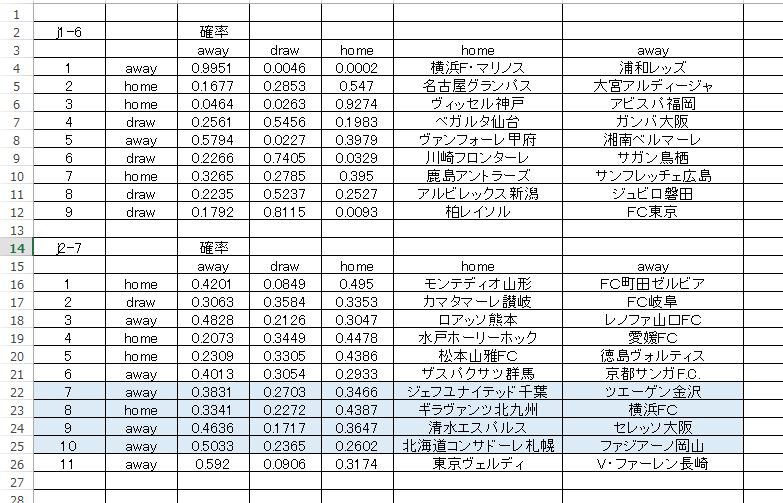
ディープラーニングの活性化関数は RectifierWithDropout、クロスバリデーションはトレーニングデータに対して nfolds 5 行っています。設定などは Jリーグ サッカー勝敗予想とディープラーニングについてで書かれている内容と同じです。
大滑り するかもしれませんが、試合経過を楽しみたいと思います。あと、それぞれの確率にも注目してほしいです。なお、確率の表示順番で 左がAWAY となっていますので注意してください。
第836回トトくじ の結果と検証 データの性質を考える
やっぱり大スベリしました。ぜんぜんダメです。
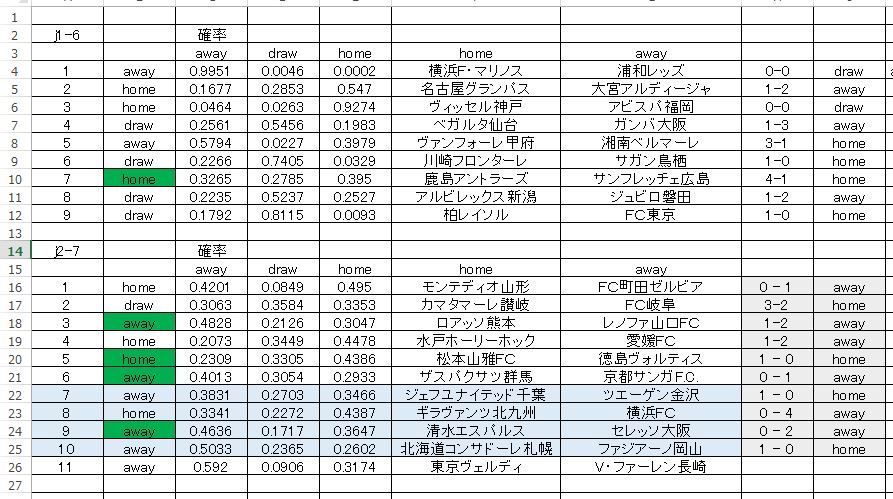
グリーンが正解枠です。第一候補がほとんど当たっていません。正解枠を第二候補まで広げてみても意味のある予測をしているとは言い難いです。一応 J1、J2 ともにデータとしては 今季リーグ戦の累積データを使っています。このことから次のように考えました。
今使っているデータ構成は、ランダム性が強い。したがってパターンを学習しても予測に反映されにくい。
参考として、データ量を制限した予測が以下です。J1,J2 ともに同じ様式でデータ量を制限しています。データの構成は先の予測と全く同じです。非常に少ないインスタンスで予測してみました。なおアルゴリズムは両者ともディープラーニングです。
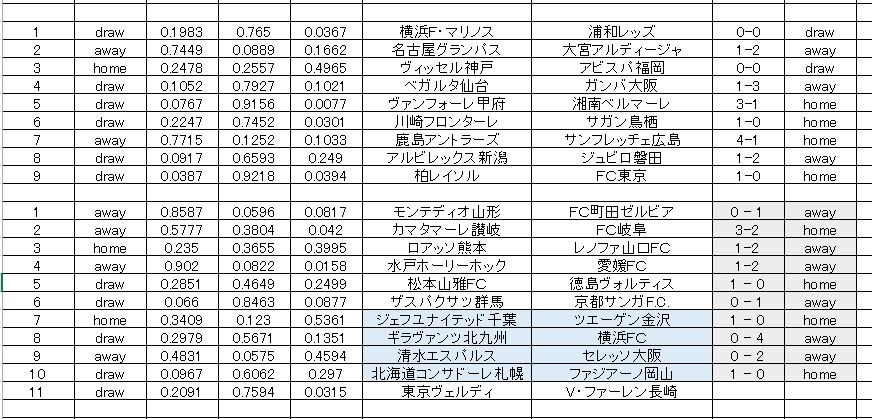
正解率としては悪いですが、こちらの方が まだ意味がありそうな予測をしていると思います。上で述べた ランダム性が高い という意味は、データに法則性や規則性がないということ。いや、まったく ない というわけではなくて、あるにはあるけれども、それが弱いということです。
したがって、いくらデータを集めても、それに明瞭な法則性や規則性がないために、特徴が掴みづらくデタラメな予測結果となって、返ってきているのではないか?
H2O においては ディープラーニングという同じスキームでもいくつかのチューニングによって性格は変化するのですが、上の予測では MAXOUT の ドロップアウト を指定して走らせています。
ディープラーニングは特徴抽出に優れているという理解でいるわけですが、それはデータの質にも左右される部分が大きい。たぶん。ここまでやってきての印象としては、ディープラーニングは確実にそれぞれのデータの特徴は掴んできていると感じています。適切なデータを与えれば まず間違いなく正しい判断を返してくれる。説明変数や目的変数の取り方を工夫する余地はありますので、いろいろ試してみたいです。
クロスバリデーションによる予測モデルの評価について
過去パターンにどれくらいフィットしているか? という考え方で推論することが成功するかどうかは、予測対象とする事象の性格によります。僕のやっている ディープラーニングによるサッカー勝敗予測 の場合は、データパターン(特徴抽出によって得られたパターン)による分類 です。
予測モデルの評価として いわゆる ブラインドテスト(目隠しテスト)つまりは 交差検定 というものをします。これは すでに分類結果が分かっているものを適当に分割シャッフルして、新たに正解ラベルを隠したままテストすることを意味します。これの正解率が高いほど優秀な分類モデルだというわけです。
しかしながら これは ランダム性の高い事象、データ に対してはあまり意味がない。なぜなら ランダム性が高い事象 というのは 再現性が低い ということになるからです。ある程度のヴォリュームで蓄積されたデータ、いわゆる累積タイプのデータにおいては ランダム性が高いものほど交差検定で良い成績を収めたとしても、実戦ではまったく役に立つ予想、予測はできないと思います。
逆に言えば、再現性の高いデータ ならば、ものすごく正確な予測ができます。僕がデータ量、インスタンスを極端に減らしたのは、サッカーの勝敗に寄与する 属性 attribute には決定的要素がなく、再現性も低い からに他なりません。事実、いわゆる 変数の重要度 というものは分析するデータによってまったく変化します。つまり 決定的に重要な変数というのはないのです。毎回、毎節 変わります。
話をこのセクションの冒頭に戻しますと、特徴抽出によって得られたパターン というのは毎回 違うものだということです。これで過去データに対するフィット具合から勝敗を予測しても上手くいくはずがない。だから上の 参考として挙げた予測結果 ではクロスバリデーションは行っていません。意味がないからです。もし交差検定をしていたら、全く違った予測結果が示されるはずです。おそらく上に挙げた例よりも悪くなっているだろうと思われます。
サッカーの勝敗分類においては決定的なデータパターンはない。あるいは、あるにはあるけど、それが弱い。ディープラーニングによって確実に特徴は捕らえられているけれど、予測精度はまだまだ低い。
予測精度が低い原因はデータ構成、構造にあると思っています。H2O の性能が低いわけではありません。これまでいろいろ試してみて、その分類能力はじゅうぶんに高いと感じています。パラメーターのチューニングよりも データを見直す方が良いはずです。
以上、このセクションで述べてきたことに関連する良いテキストがありましたのでリンクしておきます。
「そのモデルの精度、高過ぎませんか?」過学習・汎化性能・交差検証のはなし – 東京で働くデータサイエンティストのブログ

今年の1月にこんな話題を取り上げたわけですが。この記事の最後にちょろっと書いた通り、実際にはこういう”too good to be true”即ち「そのモデルの…
基本的に 交差検定の有用性 について論じている内容であり、機械学習全般において役に立つ良い内容です。特に気になった部分を引用しておきましょう。
また、これは割と嫌な話ですが「交差検証したからと言って汎化性能が確保できるとは限らない」ケースもあるということ。特に学習データと(テストデータで はない本当の)新規の未知データとで性質が全く違うようなケースでは、いかな汎化性能の高いモデルでも太刀打ちできません。時々Kaggleでその手の データセットが出てきて物議を醸すことがありますが、実務でも同様のことは少なくないです。
赤字 は私が付けたものです。僕の作成しているデータが、引用で強調されている性質に該当するのかどうかは正確には分かりません。しかし、根拠は示すことはできないけれども、(なんとなく直感ですが) どうやら僕の 自作データ に対する見方は当たっているような気がしています。
クロスバリデーションは有益であるけれども、信頼できる結果を期待するのには前提条件が必要だということ。それは、データの性質が ある程度 似通っていなければならない。つまりはデータから推測される結果の再現性が高いほど予測は上手くいきます。当然のようなことを書いていますけれども、ランダム性の高い事象を予測することは非常に難しいことだということです。


コメント