
トト予想 年度や試合日よる時系列変化を捉えることができるだろうか?
現在、トト予想において経年による変化を予想に反映させるためにいろいろテスト中です。まず手始めに、年度 それから 試合日 という二つの属性をプラスして GBM で作成した予測モデルを見てみます。
比較のために 時系列あり、なし の両方を並べてみます。
このテストはすべて 点差分類 として計算したものです。点差分類 とは、ホームからアウェイのゴール数を単純に引き算したもの。これを名義属性の目的変数として分類予測します。
時系列なしGBMによる予測モデル
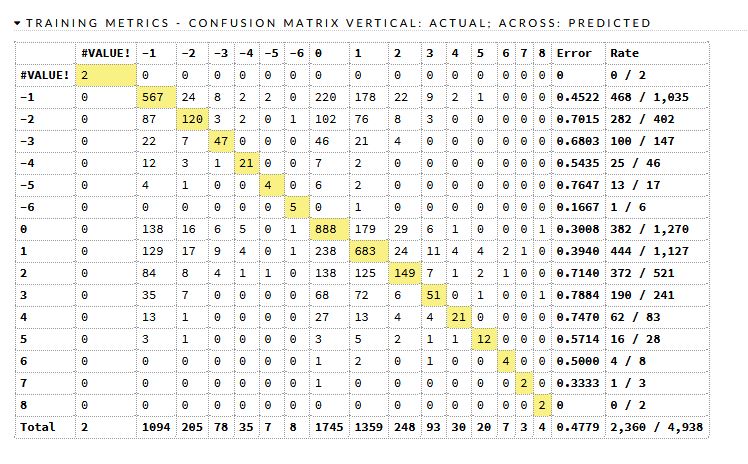 これは GBM 予測モデル時系列なし です。表の右端から二列目、ここがエラー率です。単純に考えてこの数値が低いほど正しく予測されているということです。画像では 0.4779 となっていて、およそ半分において誤った予測がされているという意味。
これは GBM 予測モデル時系列なし です。表の右端から二列目、ここがエラー率です。単純に考えてこの数値が低いほど正しく予測されているということです。画像では 0.4779 となっていて、およそ半分において誤った予測がされているという意味。
時系列属性を付けたGBM予測モデル
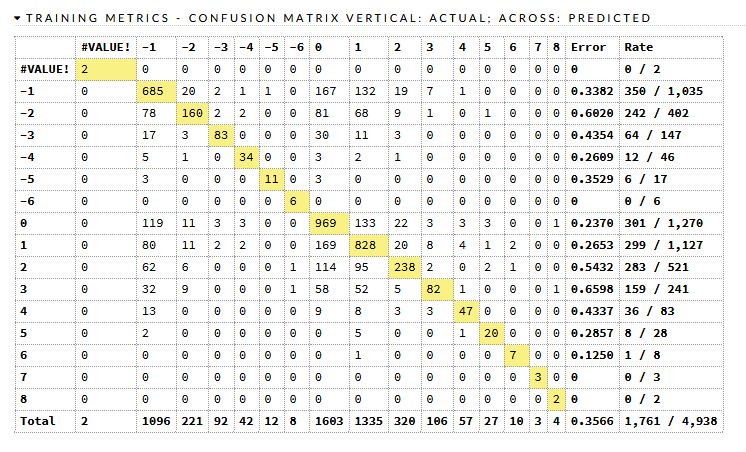 上は 時系列ありGBM こちらは 0.3566 となっていて、少し改善されているように見えます。しかし良くはないですね。
上は 時系列ありGBM こちらは 0.3566 となっていて、少し改善されているように見えます。しかし良くはないですね。
時系列なしDL予測モデル
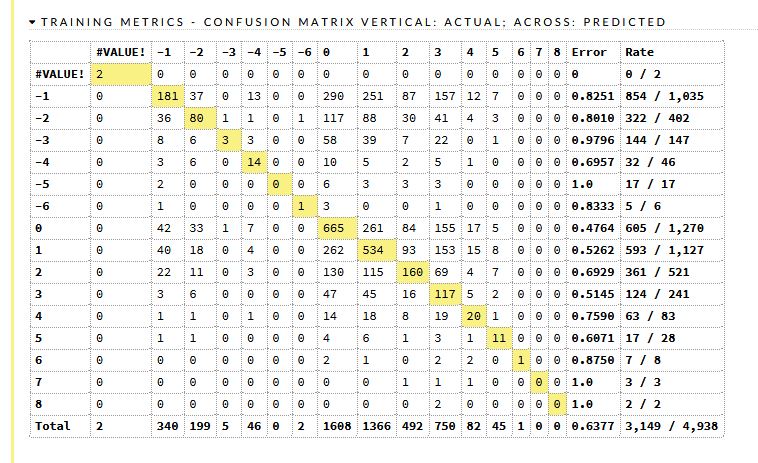
GBM と比較すると極端に悪くなります。
時系列付きDL予測モデル
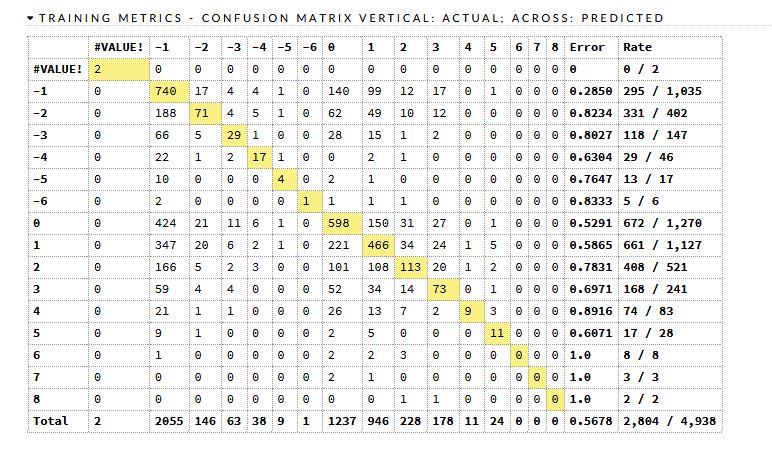 時系列属性を付加すると少し良くはなりますが、それでもGBMと比較すると悪いです。
時系列属性を付加すると少し良くはなりますが、それでもGBMと比較すると悪いです。
時系列属性の有り無しによる予測モデル比較のまとめ
以上、簡単ですけど比較してみました。予測モデルにおいての性能比較は、予測モデル構築の段階では明らかにGBMが優るのは分かっていたんですが、注意してほしいのは、実際の予測においては必ずしもこのような数値に準じて結果が示されるというわけではないということです。
917回トト予想においては、時系列属性なしデータで予測させましたが、DLの方が良い結果を出していました。テスト段階では明らかにGBMの方が信頼できそうだったにもかかわらず。
いろいろと形を変えてテストしてみないと分からないことも多いです。
年度と試合日のデータ化について
今回のテストにあたり、年度、それから試合日について 「どうデータとして扱うか?」 という問題がありました。詳しいことや、これが正しいやり方 というものについては自信がありませんので書きません。ただ自分がやった方法は以下です。
H2O にデータを読み込ませた後、パースをする前に属性を設定します。この時に、TIME という属性に変更するだけです。おそらくこの作業だけで 時系列データ として認識されるのではないかと思います。(間違っているかもしれません)
ちなみに上で行ったテスト用データというのは以下のようなものです。
2012~2016年度 と、2017年度の直近の試合まですべて
J1、J2、J3、ルヴァン杯は2014から。
以上をひとまとめにしたデータです。データ構成、たとえばステージごとにデータを分割などすればまた結果は変わってきます。どの形態がベストなのかについても検証すべきだとは思います。
追記 トレーニングデータの構成を変えるとやはり結果は大きく変わる。
ここでいう 構成 とは、属性数のことではなくて、 過去データのまとめ方 についてです。属性は年度、試合日などの時系列情報、対戦カード、スコア情報だけでじゅうぶんだと思っています。
一部、二部 といったチームのカテゴリーの移動をどうデータに反映させるのがベストか? これはすごく難しいです。試しに現在 組み合わせを変えてトレーニングデータを作り、その結果を検証しているのですが、細かい点ではやはり違いが出てくるようです。
1部、J1 については J2 を含めてトレーニングデータを作成した方が良いと思います。ルヴァン杯に関しては 含めるか、含めないか? 両方やってみる価値はある。
J2 はどうか? 上に上がるチームもあればJ3落ちとなるケースもあったりで、ちょっと難しい。もちろんひとつのカテゴリーの年度データだけで予測するのもアリ。そう考えると 「いくつか予測モデルのパターンを作って全部をやってみる」 という方向もありですね。
どれかひとつに固執するんじゃなくて、全パターンやってみて、たとえば出力結果を合成してみるとか、そういうのもいいかもしれません。
経験から言うと、アルゴリズム設定を極端に変えなければ出力結果も極端には変わらないです。なので、いくつか組み合わせを変えてトレーニングデータを作った方が良い。
追記 時系列属性は付けた方が良い。
いろいろテストしたんですが、過去データが大量の時は年度だけでも認識させて分類予測した方が良い。
たぶんちゃんと認識してると思いますし、確実に予測に影響を及ぼしている。一番の問題は、やはりデータ構成です。
カテゴリーをどう扱うか? j1、j2、j3、それからカップ杯。これらカテゴリーの違う大量のデータをどういうふうにまとめて トレーニングデータ とするか? これが一番予測モデルに影響するんじゃないかと感じます。
ちなみに年度や試合日は、エクセルのDATE関数でいろいろな形で変換します。どれがベストかはやってみて判断するしかないです。
あ、あとまだ試していませんが、時系列予測に特化したアルゴリズムをやってみたい。

コメント