
直近のデータで予測させてみると出力はどう変化したか?
前回記事からの続きとなります。興味がある方はさかのぼって読んでください。
さて、今季リーグ戦の累積データから次節の結果を予測するという試み。累積データでは、何をどういじっても予測結果、つまり出力が変化しないケースがあります。事前の考察で、トレーニングデータを変化させれば出力もおそらく変わるだろう という推察のもとに、実際にトレーニングデータのデータ量を制限して予測作業を行いました。
具体的には、直前の2節分、3節分 というようにデータを区切り直して、それぞれを教師データとして与えてみる というやり方です。
分類スキームは H2O-3 の GBM に統一しました。注意点としては データのバランス にあります。現在行っている予想、分類は 3WAY方式 ですので、圧倒的に DRAW が少ないです。累積でも少ないのに、データ量が少ないと比率としてはもっと低くなります。本来ならダミーデータを足すなどしてバランスを取った方が良いのかもしれませんが、今回は何もせず、そのままの形で予測させてあります。まずは予測結果の一覧表を載せます。
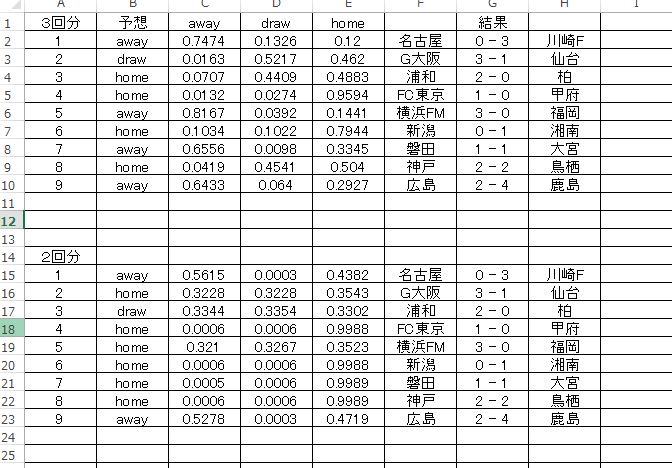
見たまんまですが少し説明します。まず、トレーニングデータとして参照した 直近のリーグ戦のデータ数の違い を見て欲しい。下が 予測回の前2節分のデータ、上が前3節分となっています。数値はそれぞれの確率です。並び順はいつものように左がAWAYですので勘違いしないように。
これは私の見方、感触なんですが、累積データによる予測とは、そんなに大きく逸れた出力結果ではない という感じがします。細かい点では違いは当然ありますが、全体的な予測方向はほぼ累積データを使用した予測と同じ方向性を持っている。
何より興味深いのは、やっぱり 広島ー鹿島 で、データ量を直近のものに制限した上のケースでは、ちゃんと 鹿島の勝ち と予測されていることです。累積データでは、属性をかなりいじって試行してみましたが、絶対にこの結果は得られませんでした。
あ、大事なことを忘れていました。説明変数について少し説明します。
このテストではフットボールラボのデータをそのままマトリクスにして使っています。テストで除外した変数は以下です。
シュート数、枠内シュート数、PKシュート数、シュート成功率、PK成功率
以上5項目ですね。これらの変数は出力に大きなウェイトを占めると考えられるので、ここが実際のスタッツと逆になっていたりすると 他の変数との関係による予測 が、台無しになってしまうような気がしています。
この予測のやり方、考え方の汎用性について
2回分と3回分の予測結果を見比べると、3回分の直近データを使った予測はかなり良いと感じます。
しかし、おそらく上で述べた予測のやり方には汎用性はないです。残念ですが これがいつでも最もパフォーマンスを発揮できるやり方 ではないです。こういうことはこれまでにもいくつか経験してきました。開催回によって予測の安定性というのは、かなりブレが生じます。安定した結果を得られる予測手法を構築することが目的でもあるのですが、かなり難しいと言わざるを得ません。


コメント