

Jリーグも開幕戦が始まってしまいました。機械学習を使っての予想も もう何シーズンになるか、ずーっと結果が出てないです。同じことを繰り返しても意味がありませんので、なんとか新しい試みを考えています。
以下に現状で考えてるヒントらしきものを整理しておきます。
ただの傾向分類ではダメ 時系列での変化を捉える工夫が必要だ
データの質が高ければ、それだけで予測精度も高くなります。当然のことなのですが、これをもっと考えてみます。
時系列で変化がないデータには、たとえば 写真、画像 の分類があります。これらは 静的データ分類です。数多くのデータを集めれば おのずと特徴が現れてきて分類精度が高まるタイプです。一般的なディープラーニングは これです。
動的データの代表は 株価、為替 などや、私がやってるスポーツの勝敗予想 など。これらは 名義属性の特徴といったものが時系列で変化する。常に一定の量的尺度で測ることができません。
たとえば 広島 と聞いて、だれもが強いチームだと言う。しかし格下に負けることもあり、連敗もあり得ます。名義が特徴を表わしているのではなくて、その時のなんらかの条件が勝敗に関与しているわけで、同じ名義の特徴をずーっと保持しているわけではないということ。
金融分野では、たとえば重要な経済指標とか、事件事故、その他あらゆる事情によって値動きがありますし、スポーツ分野では、主要選手のケガ、移籍など、あるいは監督交代などといった事情で おおきく傾向が変わったりします。それに対戦相手の事情もおなじように変化しているので、常に一定の条件で観察できるタイプのデータではありません。
まずはこういった基本的な知見を得て、どういったデータを使う、あるいは作る必要があるのか? そこから考えなければ進歩はありません。
株価予想をサッカー勝敗予想に応用する
一見すると奇妙な小見出しに見える、このタイトル。株価となんの関係があるんだ? いや、じつは考え方が似ていて 非常に応用が利くんじゃないと思っています。
元ネタは ほかの記事でも取り上げている以下の記事。

我ながら しつこく読んでいる記事です。以下に同じ記事をリンクした私の記事です。
元ネタは内容が示唆に富んでいて、興味深いです。以下に考え方のヒントを引用しておきます。
「モデルツリー」と呼ばれるAIの分析手法は、過去数年間の市場データパターンからいくつかの局面を作成、局面ごとに重要な経済指標を選び、株価を予測す る。最適なサンプル期間と経済指標を毎回選び直すため、市場に変化が起きた場合でも柔軟に対応できる点が特徴だ。
上の文章を スポーツ予想に置き換えて 読み込んでみる。
過去の勝敗パターンからいくつかの局面を作成、局面ごとに重要な指標を選び勝敗を予測する。最適なサンプル期間と指標を毎回選び直すため、チーム環境に変化が起きた場合でも柔軟に対応できる。
以上、適当に読み替えてみました。
こういった予想は、みなさん意識しないでもすでに脳内でやっています。たとえば、誰々が出場停止だからとか、連戦で疲れているとか、リーグ戦じゃないからスタメンを総入れ替えしてくるんじゃないだろうか? とか・・いろいろありますね。
こういった もろもろの予想を取り入れた機械予測をやってみたらどうか?
以前から、こういった種類のテキスト情報を機械予測に取り入れるには どうすれば可能なんだろうか? という考えはありました。ただ実践的な方法が分からないのですね。あらためて考えると、そういう指標を、オリジナルな指標を考え出せばいい。
試合結果にあきらかに影響するであろう指標・・為替などに影響力のある もろもろの経済指標みたいなものを作ればいいんです。ただし、これには問題点があって、直前になるまで情報が手に入らないという欠点があります。具体的にはスタメン情報です。主要メンバーのケガ、出場停止などは事前に分かりますが、スタメンは分からない。
もうひとつ、それは体調です。これは個人的なものであり、そんな情報はどこにも公開されません。あと、監督の指示、考え方、作戦など。ある程度 情報通になれば予測もつくのでしょうけど、こういった情報をどうやって機械に伝わるようにデータ化すればいいのか?
まず最適なサンプル期間と重要指標を選ぶ
とりあえず手を付けなければならないのは、最適なサンプル期間の設定。どれくらいの期間をデータとして考えればいいのか?
あんまり古いデータは必要ないというのは簡単に理解できます。メンバーが全然違う時のチーム状態で、今を予測することには無理があることは誰でも分かる。最適サンプル期間を見極めることは難しいですが、僕は直近のデータでいいと思います。過去対戦のデータも参照することはありますが、結果的に 「そうなった」 というだけで、検証してみる価値はあるかもしれませんけど、結果予想に寄与してるデータだとは思えません。
重要指標についてはどう考えればいいのでしょうか?
結果に直結する要素として誰もが思いつくのが主要メンバーの変化です。それとサブメンバー。移籍情報など。
監督交代も重要指標といっていいかもしれません。あと、公式戦のインターバルとアウェイ転戦などの移動負担による体調管理など。これらの要素がどれくらい結果に影響しているのか 知見として利用できるものなのか データ分析してみなければなりません。
指標として見落とされがちなのが、経済的側面です。選手価値というのは金額で測られているのは周知の事実。選手獲得に大きな負担をしているチームほど強いのは当然です。実際にはズレもあるのですが、基本的な知見として、そういう見方もあることは頭に入れておくべきだと思います。
具体的データ作成については追記します。
サッカー予想に特化したデータとは?
何度も書いているのですが、サッカー勝敗予測用のデータには大前提があります。それは 「予想段階で知りえる情報しか使えない」 です。しかもデータを整えて予測する時間も必要となってきます。
これから結果の分からない未知なモノを予測するわけで、現在知ってる情報で判断するしかないわけです。直前に どのチームに対してどんなパフォーマンスを示したか? は分かります。しかし同じようなパフォーマンスを次の試合相手に示せるか? というと それは誰にも分かりません。
データ作成の準備段階として、ひとつのアイデアを挙げたいと思います。これは僕自身が以前にも行ったことがあるものですが、もう一度取り上げて考える材料にしてみたい。
以下の画像は 仙台 と FC東京 について 1節 の対戦組み合わせを同じ表に並べてみたものです。
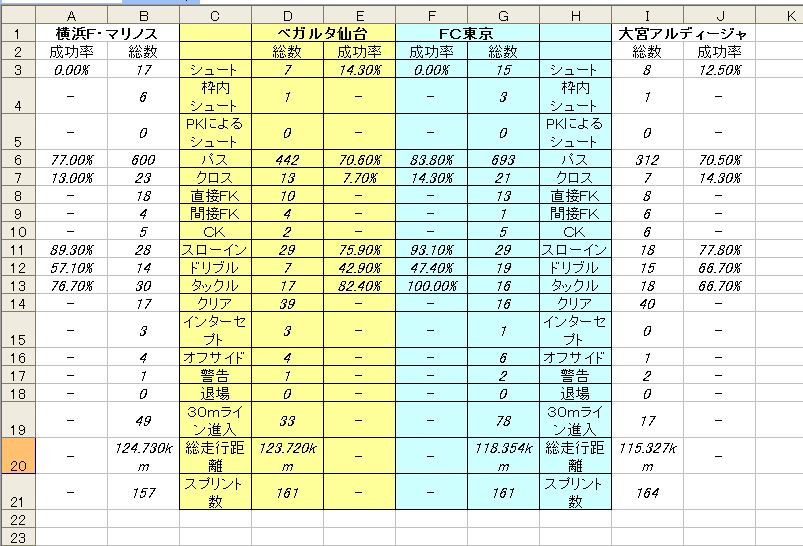
この意味について説明します。
今回で示したパフォーマンス が、次回の結果に どれくらい相関があるか?
対戦相手が違うので、こんなことに意味があるのかどうか? 正直言ってよく分かりません。しかし改めて見てみると、やはり FC東京 のほうが良いパフォーマンスを残しているように見える。
もう一つ サンプル を挙げます。
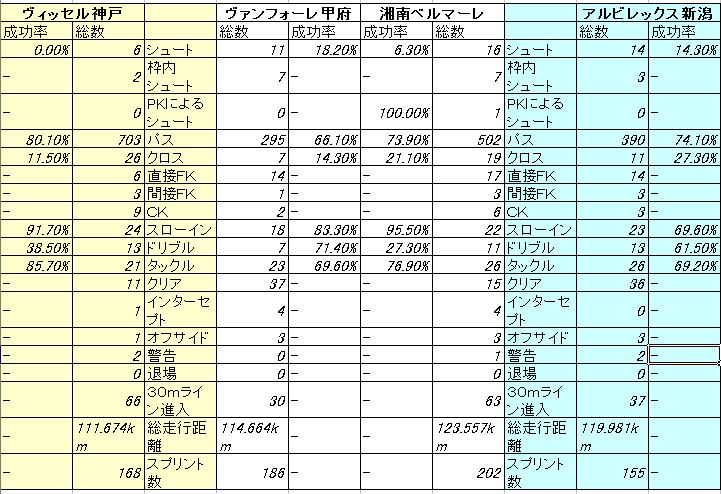
データの対比方法は先と同じです。1節のスタッツを2節の対戦チームで比較します。
ここで目を引くのは パス と クロス の成功率です。FC東京も神戸も パスとクロスの成功率は相手チームより優っているのが確認できます。したがって 30Mライン進入回数も多くなる。
主に攻撃面を見ていますが、パスがよく通ることはチーム全体が機能していることを示す指標になるんじゃないかと思います。
データ比較による分析については目視による考察ではなく、機械学習による判断をしたいと思います。
今回はここまで。また追記します。
説明変数にチーム名とか個人名などの 固有ID を使うことの意味について
データ本体に 固有ID を使うことについて、タイムリーな記事がありましたのでリンクしておきます。
「正答率100%」になってしまう機械学習モデルの例を挙げてみる – 東京で働くデータサイエンティストのブログ

何か僕がシンガポールに出張している間に妙なニュースが流れていたようで。京大ビッグデータ副作用論文。機械学習知らない私でも疑問なのは、@sz_drさんも指摘してる…
僕も機械学習に興味を持った初期のころから 固有ID は使っていました。チーム名 なんかが一番よい例です。数値などと違って固有IDは、それ自体には 識別する という意味しかありません。その文字列自体が 何らかの意味・・・つまり 強さ とか 長さ とかいった 定量的要素を持つわけではなくて、ただ他のものと区別するだけのものである場合、これを説明変数に使うと おかしなことになる ということについて書かれています。
つい勘違いして、だれでもやってしまいがちな典型的誤りです。
分析の元となるデータでは識別のためにカラムを作成しても、分析用データには使わないほうが良いです。説明変数として使う名義属性は、定性的性質を持った文字列を考えた方がいいです。
チーム名 は定性的ではないのか?
この見方には僕は否定的です。なぜなら時間とともに性質が変化するものだと考えるからです。1年前と現在ではチーム内容、状況が変化していると思います。
僕自身の過去の勝敗予測ではチーム名も使っていました。何らかの傾向が存在するかもしれないですが、説明変数に使っても あまり予測精度の向上には寄与していないと感じます。何年も前からの累積データで使用するのもアリですが、やはりチーム名が性質を表わしていると考えることには無理があると感じます。
どうしても固有IDをデータとして使いたい場合はどうするか?
単純に考えれば、名義属性(nominal) を 数値(numeric) に変換すればいいだけです。ただし数値の場合には 大小 という概念がどうしてもつきまといます。これが予測に悪影響を及ぼす可能性があります。IDがふたつ、あるいは三つぐらいですと、0、1、-1 などと識別させることは簡単ですが、これが何十にもなってくるとあんまり好ましい状況ではなくなってくると思います。
最新ヴァージョンのWEKAや、H2O においては、チーム名などのカテゴリ変数をデータに混ぜ込むと、読み込み自体を拒否する仕様になっていると思われます。あるいは読み込みは可能ですが、予測をする段階でエラーになります。
かつて使っていた 古いヴァージョンのWEKAや、H2O ではカテゴリー変数を混ぜ込んでの予測も問題なく動いていましたので、どうしてもカテゴリ変数を数値変数と混ぜ込んで予測を試してみたい場合は、古いヴァージョンをオフィシャルサイトから探して使ってみるのも選択肢としてはアリかもしれません。

回帰分析 (Regression) の場合はすべて数値データ、分類 Classification においては、目的変数のみカテゴリ変数とするのが基本のようです。
ただいま工事中 しばらくお待ちください。つづく


コメント