
チーム別にトレーニングデータ、テストデータを作って予測する
今後の予測については、チーム別にデータを作って行うことにします。面倒な作業にはなりますが、より予測精度を高めるためにはどうしてもチーム別に行う必要がある。手順をざっくり説明すると以下のようになります。
1、まず今季累積データ・・正規の対戦履歴を節ごとに時系列マトリクスにする。
2、これをチーム別にソートする。
3、ソートされたチーム別データがトレーニングデータとなる。
トレーニングデータのホームとアウェイ これをどう考えるか?
さて、累積時系列データ ですが、これをチーム別にソートした場合、問題になってくるのはホームとアウェイの扱いについてです。これはどう考えればいいのか?
チームスタッツ というのは基本的に行列が一致していなければなりません。つまり同じチームでもホーム時のシュート決定率とアウェイ時のそれとは同じ属性として扱ってはいけない。例を挙げると以下のようなことになります。
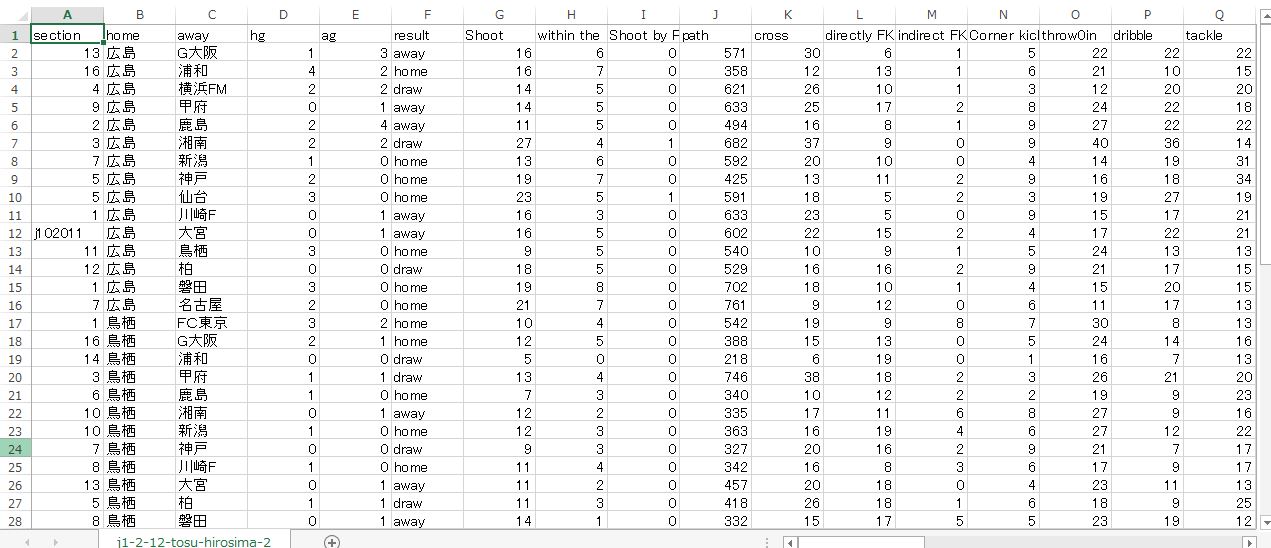
上の画像は J1 2nd 鳥栖ー広島 についてトレーニングデータを作成中のもの。
各属性の横の並び順と縦は完全に一致していて完全なマトリクスとなっています。これのどこが問題なのか? まず与えられた課題に対して忠実にデータ構成がなされていません。つまり課題は 鳥栖ー広島 なので鳥栖の列に広島のデータを一緒に並べているのがまずいです。この場合、鳥栖のホーム戦の特徴を抽出しようとしているのに対して、他チームのデータ(広島)が同じ属性に混じるのはトレーニングデータとしては不適切なのではないか。このように考えると広島がホームの試合だけをケーススタディとしてトレーニングデータとするのが適切です。しかしアウェイ側はバラバラのチームが同じ列に並べられています。これは問題ないのか?
これは 対戦相手のデータ という意味合いから言えば 問題なし だと判断しています。整理すると、このトレーニングデータは 今季の広島のホーム戦における特徴を表したデータであるわけです。
逆に考えると、予測対象試合におけるアウェイ側でも同様のトレーニングデータも作る必要があります。上の例でいうと、今季広島のアウェイ試合だけを抜き出しておなじようにマトリクスにする。
以上をまとめますと以下のようになります。
予測対象試合についてはふたつのトレーニングデータを作る。ホームは今季のホーム戦累積データを、アウェイも同じく今季のアウェイ戦の累積データをそれぞれトレーニングデータとします。
テストデータについてはどうするのがベストなのか?
テストデータは上の 鳥栖ー広島 を例に挙げると基本的にトレーニングデータと同様な作り方をします。つまりホーム側に鳥栖のデータ、アウェイに広島のデータを入力します。実際にデータを走らせる場合には、ホームデータとアウェイデータ どちらも兼用でOKだと思います。
問題は どのスタッツを流用するか?
回帰分析で各属性の値を推定する手法もありますが、これは原理的に不可能っぽいです。重回帰分析というのは相関関係にある数値が分からないと推定のしようがないからです。なんにもデータがない状態からは特定の数値を求めることは不可能です。唯一考えられるのは 平均値 というやつです。しかしこの考え方はあまり上手く機能してくれるとは言えません。なぜなら 偏差 があるからです。対戦相手によって各属性の値はかなり違ってきます。平均値は総合的な強さを測るには使える手法ですが、個別の対戦結果を予測するための数値としては不適切だと判断しています。言い換えれば リーグ順位 と同じようなものであり、予測に限って言えば、「順当勝ちするとしたらどちらが優勢なのか?」を推定する手段として有用なだけであり、局地的な偏り・・つまり波乱のような予測をするためには適切ではありません。
さて、これまでは直前のスタッツをホームアウェイ関係なしに、そのまま流用していたのですが、今回考えた方法は○○○○です。あえて伏字にしましたけれども、正直言ってこれは本当に難しい。テストデータに入れる数値群で吐き出されてくる結果はまったく違ってきますから。自分の中では 「これだ」 というものはあるのですが、今はまだ確証が得られていません。試行中ということ。
ある意味 核心的情報 ともいえるので、今後も公開はするつもりはありません。探求心のある方はいろいろ試してみてください。
上記の予測手法で実際に機械予測してみた結果を載せておきます。トトワンという予想サイトで、今節だれもマークできなかった3枠についてテストしてみました。
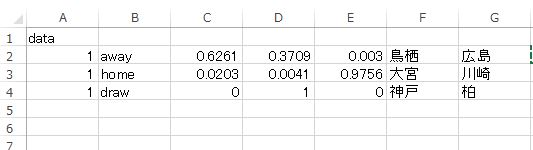
数値の見方はいつもと同じで、真ん中ドローをはさんで左側がアウェイとなっています。まあ、これだけ見ても 「どうってことないんじゃねーの?」 と感じるかもしれませんが、この結果を人力予想じゃなくて、機械的に導くのは大変なんです。しかも同じ方法で。鳥栖-広島、大宮ー川崎 はホーム側のトレーニングデータによる予測、神戸ー柏 については アウェイ側のデータによる予測結果です。その他はまだテストしていませんので、どれくらい汎化性能があるのかは分かりません。
注1.大宮ー川崎 のテスト検証においてミスがありました。表の結果は正しくは DRAW です。テストデータに入力ミスがありまして、再検証の結果、何度やってもドローの結果しか得ることができませんでした。
テストの結果、「少々できすぎかも?」 という疑いはあったんですが、案の定 勇み足で致命的なミスを犯していることに気が付きました。j1-2-12 大宮ー川崎 の、あの結果を偶然ではなく必然で導き出すのは不可能なんじゃないかと感じます。
ちなみにアルゴリズムはすべてディープラーニングです。関数は MAXOUT を使用しています。
仮にこの手法を運用するとなると、常に二通りの出力が得られます。それらは同じケースもあるし、神戸ー柏 のように ダブル で出力されるケースもおそらく多いと思われます。上の予測例では 神戸ー柏について 神戸の勝ち という出力がホーム側データで得られています。考えられることとしては、ダブル出力があまりに多くて現実的に買えない予測となるケースです。この 「予想を絞る」 という課題に対しての答えはまだないです。いろいろ考えて試行はしてみるんだけど、これまで上手くいった試しがありません。
一番現実的方法は バラ買い理論 というやつ。2等 とか、3等当選を保証する買い方ですね。マルチ買いでできるだけ予算を抑えて当選に近づく方法は現状ではこれくらいしか思い付きません。このやり方においては 予想母体に最低でも11個の 13枠すべての正解を含んでいないとアウトです。簡単そうですがかなり難しいと感じます。
遅くなりましたが、チーム別トレーニングデータ を用いて予測させた j1-2-12節 を載せておきます。
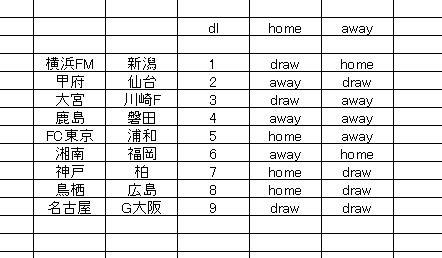
全体で5枠しか正解していません。非常に悪いです。右側2列が予想なんですが、その左がホーム側データによる予想、右はアウェイデータによるものです。この予測で使用したテストデータには従来のやり方である 直近リーグ戦スタッツ を流用しています。アルゴリズムはディープラーニングで関数はMAXOUT、これは先に示した トトワンノーマーク枠テスト と同じやり方をしています。
使っているトレーニングデータはホーム側もアウェイも先の検証事例とまったく同じものなのですが、テストデータによって出力結果が大きく違うのが確認できると思います。また出力もけっこう割れていますね。
先の検証で挙げた新しいテストデータを他の残りのチームでも作り直して、もう一度全体のテストをしてみたいと思います。
追記あるかも。
テストデータが超重要 すべては入力数値で決まる
通常の機械学習による予測分析は、なによりも 予測モデル の優劣によって決まります。このこと自体は間違いではない。ただし条件があって、テストデータにおいても予測モデルを評価したときと同じようなデータがあるケースに限って正しく予測、分類が可能となります。
私が行っている上の方で書いた予測方法のケースでは、テストデータにおいて予測モデルの評価時と同じようなデータは用意できません。それはまだ行われていないからであり、推測でしか準備できないものです。だから テストデータの出来次第によって正解率が大きく変わるのです。
現在使っているH2Oのディープラーニングなどのアルゴリズムには問題は何もありません。予測精度が悪いのはテストデータの数値が実際に行われている試合のスタッツとずれているからであり、パラメーターなどの調整で補正できる性質のものではないことは明らかです。
したがって結論を言いますと、できるだけ実際に行われている試合のスタッツに近い数値、データを用意できたと仮定すると、ほぼ完ぺきに試合結果を予測することが可能となります。この意味からテストデータが予測において超重要だということです。
トレーニングデータ、テストデータの属性項目についての注意点
H2O-3 限定での話です。最新の WEKA においてもおそらく同じではないかと思われます。
基本的にはトレーニング、テストデータの属性項目を完全に一致させます。ズレていても動きますが、管理や検証作業において煩雑になってきます。
カテゴリ分類予測のケースでは、カテゴリ属性は1個にしないとエラーになる可能性が高いです。例えば チーム名やHOME、DRAW などのカテゴリを混在させたデータでは、トレーニング過程では動いても、テストの段階でエラーが起こります。なので予測対象となる項目以外のカテゴリは削除しておいた方がよい。
現段階における試行の結果からいうと、予測モデル構築段階では 予測対象以外のデータ情報 というのは間違いなく影響します。予測モデルに明らかにそれら関係のないデータが干渉して、出力結果に影響を及ぼすものと思われます。
ベストなデータの組み合わせとは?
ここでいう 「ベストな組み合わせ」 とは、トレーニング と テストデータ のこと。そして、それぞれの 属性項目 も含みます。「そんなことが本当に予測に影響があるのか?」 という疑問があるかと思いますが、実際にいろんな組み合わせを試してみてのことなので本当に影響があるとしか言えない。
通常の機械予測では完全に両者の属性項目が一致しているのが普通です。私の場合も属性項目は一致させています。しかし、すこし工夫しないとまともに動いてくれません。とりあえず記録、備忘録として設定を残しておきます。

上の画像は j1 2ND 第12節 大宮ー川崎 のトレーニングデータ です。
黄色枠で囲った箇所 RESULT が求めたい解ですね。その左、黄色棒線でマーキングした箇所が対戦組み合わせとゴール数、そして節を SECTION として記入しています。ここで予測にまったく必要のない属性は SECTION です。これはただの目印として記入してあります。したがって予測に干渉しては困る属性なのでモデル構築の際にはすべて SECTION をオミットしています。ただし時系列での予測を考える場合には必要になると思われます。いろいろ工夫する必要はあると思いますが。。他のカテゴリーはすべて残します。
これで準備は完了、SECTION をオミットした状態でモデル構築をします。次はテストデータについてです。
テストデータを作成する際は以下のようにしています。
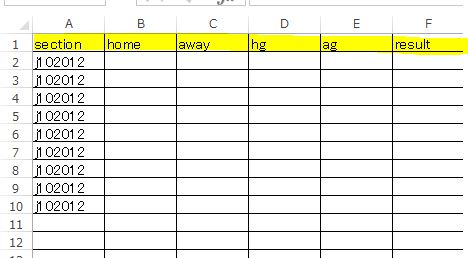
上の画像、実際に予測に使用しているテストデータの状態です。属性項目は完全にトレーニングデータの属性配置と一致させています。トレーニングでオミットした SECTION はそのまま残しておけばOKです。注意点は、画像のようにテスト用データを空欄にすることだけです。ここにデータが入っていると上手く機能しません。おそらくエラーになるはず。
実際には右側にずらっとテスト用データの数値が入ります。空欄にするのは画像とおなじ 5種類 の項目のみです。上で示された構成は一括でテストするためのもので、個別にテストデータを作る場合は1行だけのファイルでもいいです。一括のテストファイルを作成する場合は、行ごとにどのチームのテストなのかを別ファイルで管理しておく必要があるかと思います。私の場合は ヤフースポーツ におけるデータの並びを基準としています。
トレーニングデータの作り方 その2
備忘のためにトレーニングデータの作り方についてアイデアを記録しておきます。これも実際に作成してテストしたものです。じつはチーム別、ホームアウェイ別にトレーニングデータを作成して予測する方法には問題があります。それは 出力結果が非常に割れるケースが多いということ。予想としてはできるだけ精度が高く、なおかつマルチが少ない というのが理想なわけで、この観点から評価すると 結果が割れる というのは非常にマイナスなわけです。
できればひとつのトレーニングデータ、ひとつのアルゴリズム、ひとつのテストデータで予測できた方が良い。少しばかりテストしたぐらいで予測方法を評価するのもどうかなとは思いましたが、とにかくダブル出力が多すぎて話になりません。
そこでデータを合体させてしまいます。ホームデータとアウェイデータをひとつのファイルにしてしまいます。これをトレーニングデータとします。予測対象とする対戦カードのとおりにデータを合わせてしまいます。この状態のデータでもある程度は予測精度は保たれるはず。完ぺきではないかもしれませんがかなり効率よく予測できるはずです。
考え方としては以下のような感じですね。
たとえば A チームが HOME, B チーム が AWAY とします。
ホーム A の特徴と、アウェイ B の特徴を同時にモデル構築に織り込むイメージです。


コメント